When Kafka is the source of truth; schemas become your source of headaches
A presentation at Current 2022: The Next Generation of Kafka Summit in in Austin, TX, USA by Ricardo Ferreira

When Kafka is the Source of Truth; Schemas Become your Source of Headaches Ricardo Ferreira Senior Developer Advocate Amazon Web Services © 2022, Amazon Web Services, Inc. or its affiliates. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

“The major difference between a thing that might go wrong and a thing that cannot possibly go wrong is that when a thing that cannot possibly go wrong goes wrong, it usually turns out to be impossible to get at or repair.” — Douglas Adams, Mostly Harmless © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
👋 Hi, I’m Ricardo Ferreira • Developer Advocate at AWS. • Fanatic Marvel fan. My favorite characters are Daredevil, Venon, Deadpool, and the Punisher. • Yes, it’s my birthday today. 😅 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Back to basics: data serialization and deserialization © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Let’s do some 🧑💻 coding • Scan the bar code in the right for the GitHub repository. • Each example has a unique number and a use case name. • In the folder that starts with “00-” you can find a Docker Compose file to spin up a Kafka deployment for testing. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Binary Encoding with ProtoBuf, Thrift, and Avro © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Schema using Protocol Buffers message Person { string userName = 1; optional int64 favoriteNumber = 2; repeated string interests = 3; } © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
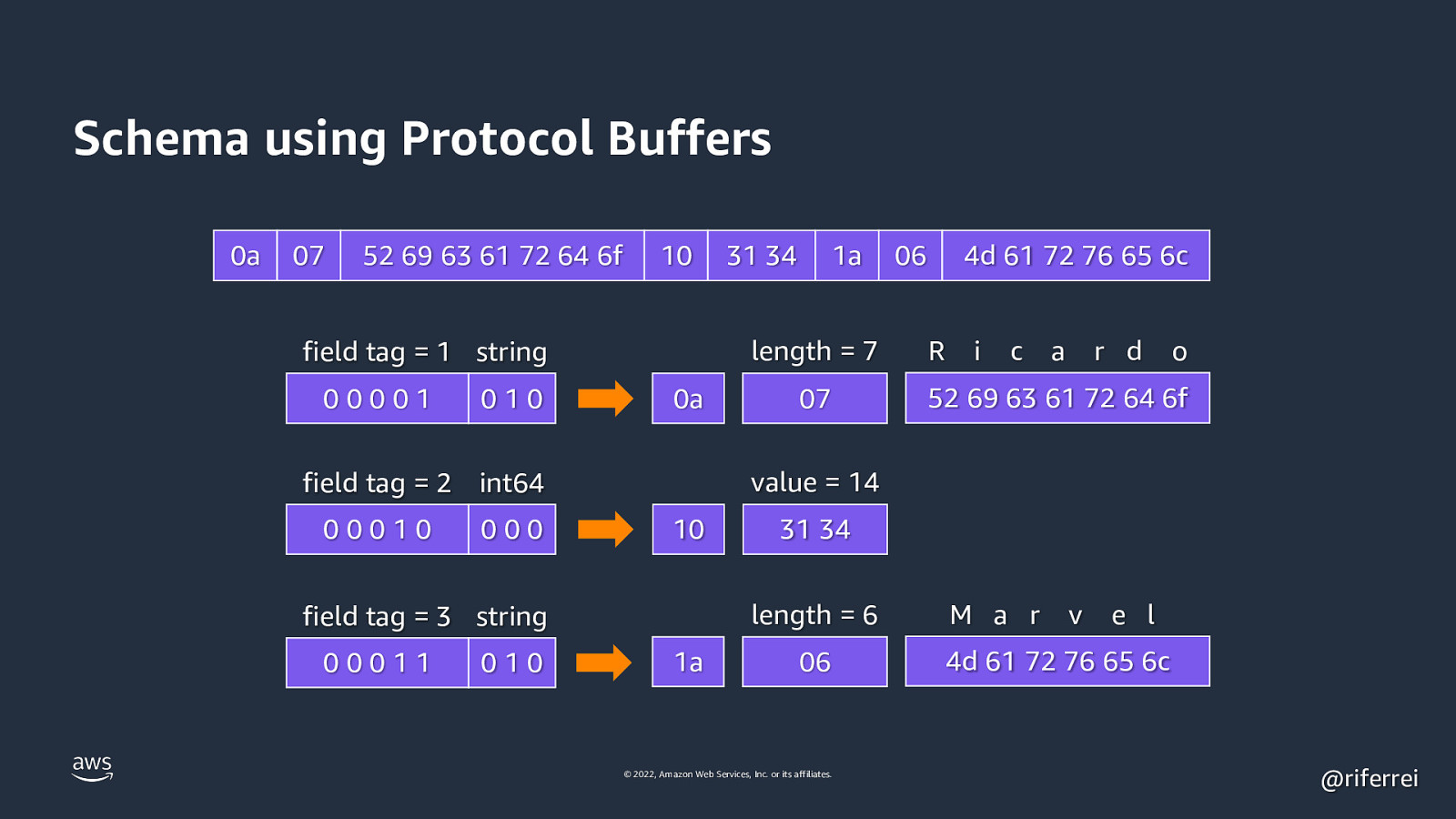
Schema using Protocol Buffers 0a 07 52 69 63 61 72 64 6f 10 010 0a 000 10 010 4d 61 72 76 65 6c R i c a r d o 52 69 63 61 72 64 6f 31 34 length = 6 field tag = 3 string 00011 07 06 value = 14 field tag = 2 int64 00010 1a length = 7 field tag = 1 string 00001 31 34 1a 06 © 2022, Amazon Web Services, Inc. or its affiliates. M a r v e l 4d 61 72 76 65 6c @riferrei

Schema using Thrift struct Person { 1: required string userName, 2: optional i64 favoriteNumber, 3: optional list<string> interests } © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
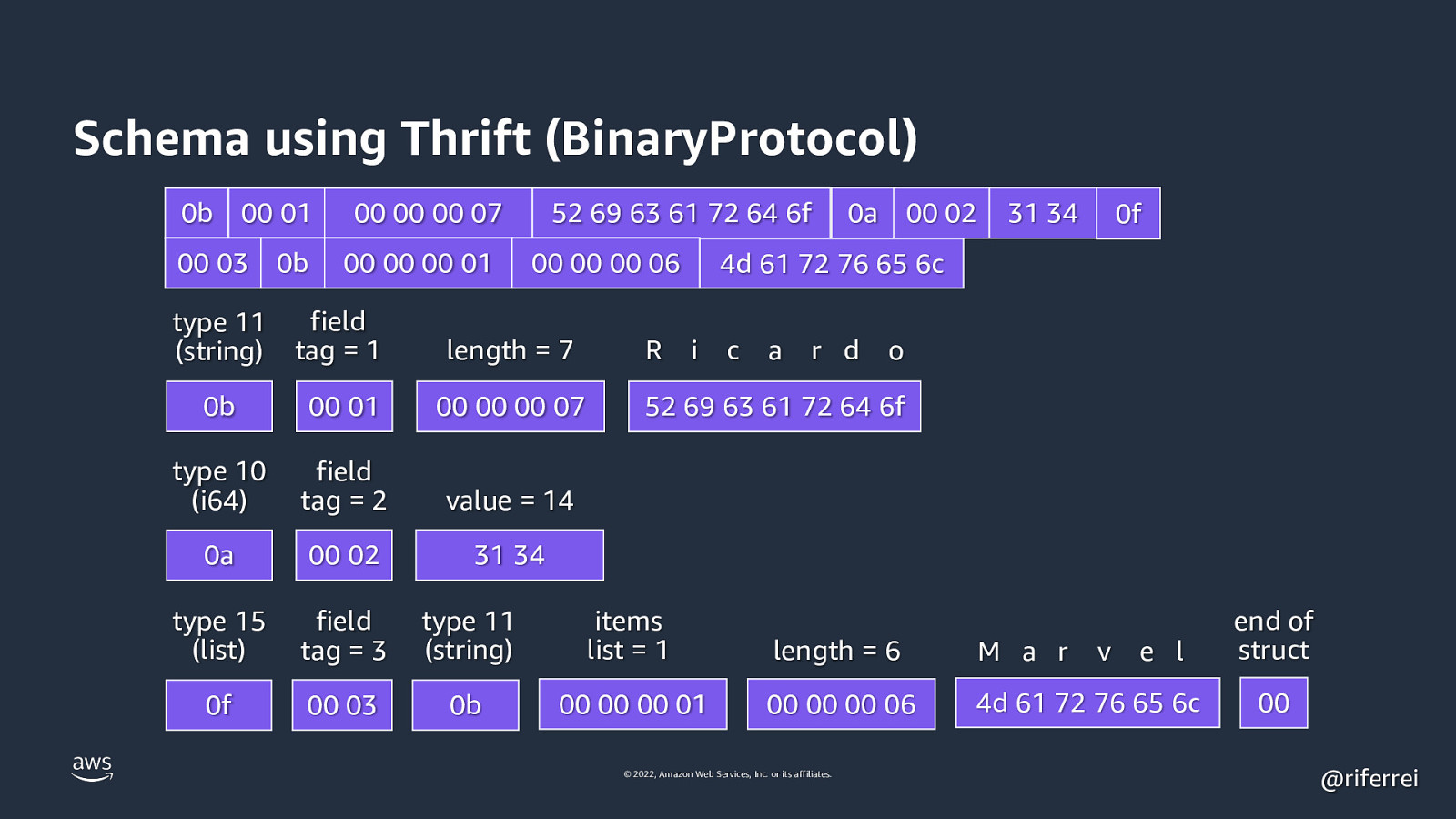
Schema using Thrift (BinaryProtocol) 0b 00 01 00 03 0b 00 00 00 07 00 00 00 01 52 69 63 61 72 64 6f 00 00 00 06 0a 00 02 31 34 0f 4d 61 72 76 65 6c type 11 (string) field tag = 1 length = 7 0b 00 01 00 00 00 07 type 10 (i64) field tag = 2 value = 14 0a 00 02 31 34 type 15 (list) field tag = 3 type 11 (string) items list = 1 length = 6 M a r 0f 00 03 0b 00 00 00 01 00 00 00 06 4d 61 72 76 65 6c R i c a r d o 52 69 63 61 72 64 6f © 2022, Amazon Web Services, Inc. or its affiliates. v e l end of struct 00 @riferrei

Schema using Avro { “type”: “record”, “name”: “Person”, “fields”: [ {“name”: “userName”, “type”: “string”}, {“name”: “favoriteNumber”, “type”: [“null”, “long”], “default”: null}, {“name”: “interests”, “type”: {“type”: “array”, “items”: “string”}} ] } © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
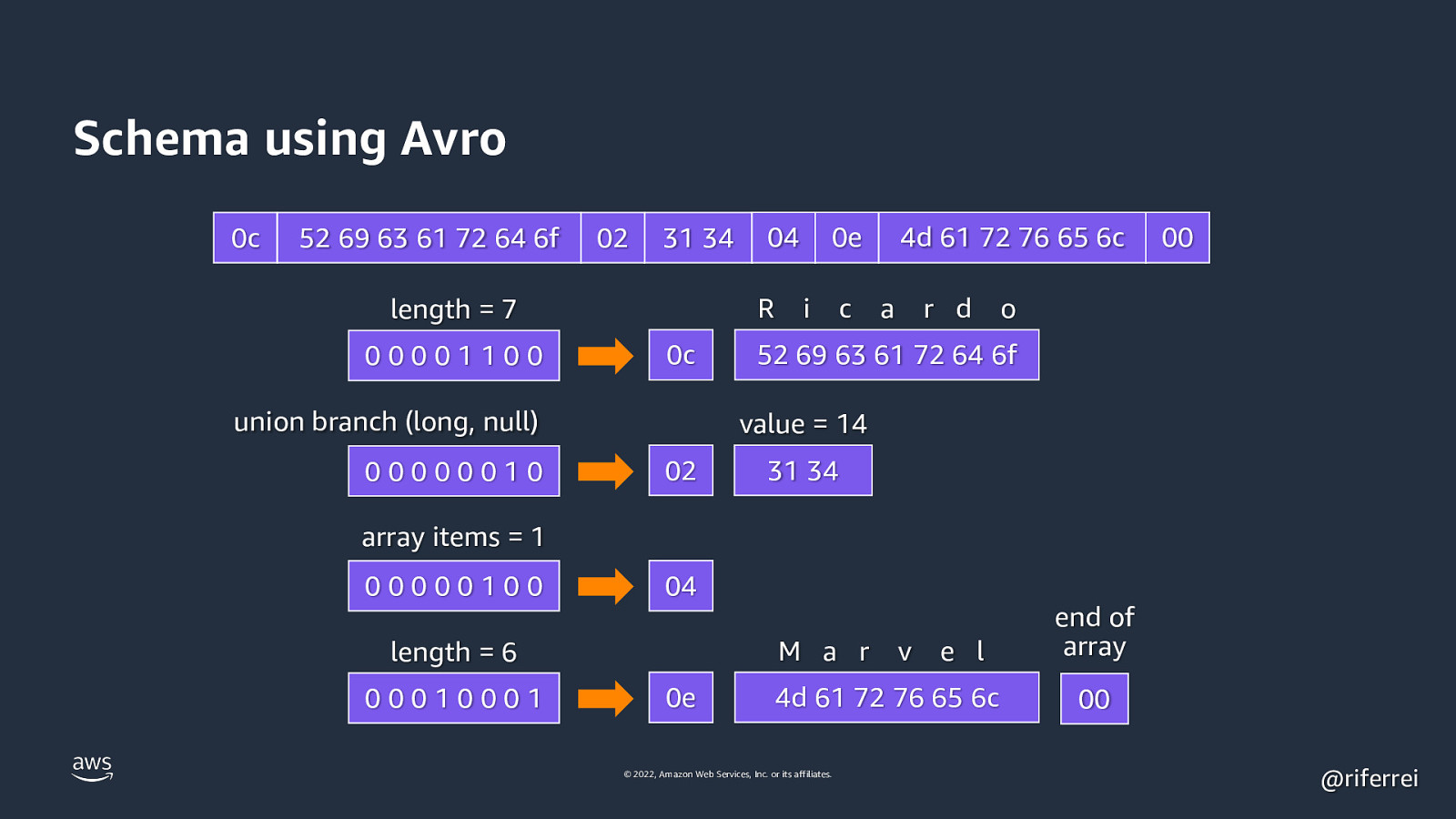
Schema using Avro 0c 52 69 63 61 72 64 6f 02 31 34 R length = 7 00001100 0c union branch (long, null) 00000010 04 0e i c 4d 61 72 76 65 6c a r d 00 o 52 69 63 61 72 64 6f value = 14 02 31 34 array items = 1 00000100 04 M a r length = 6 00010001 0e v e l 4d 61 72 76 65 6c © 2022, Amazon Web Services, Inc. or its affiliates. end of array 00 @riferrei
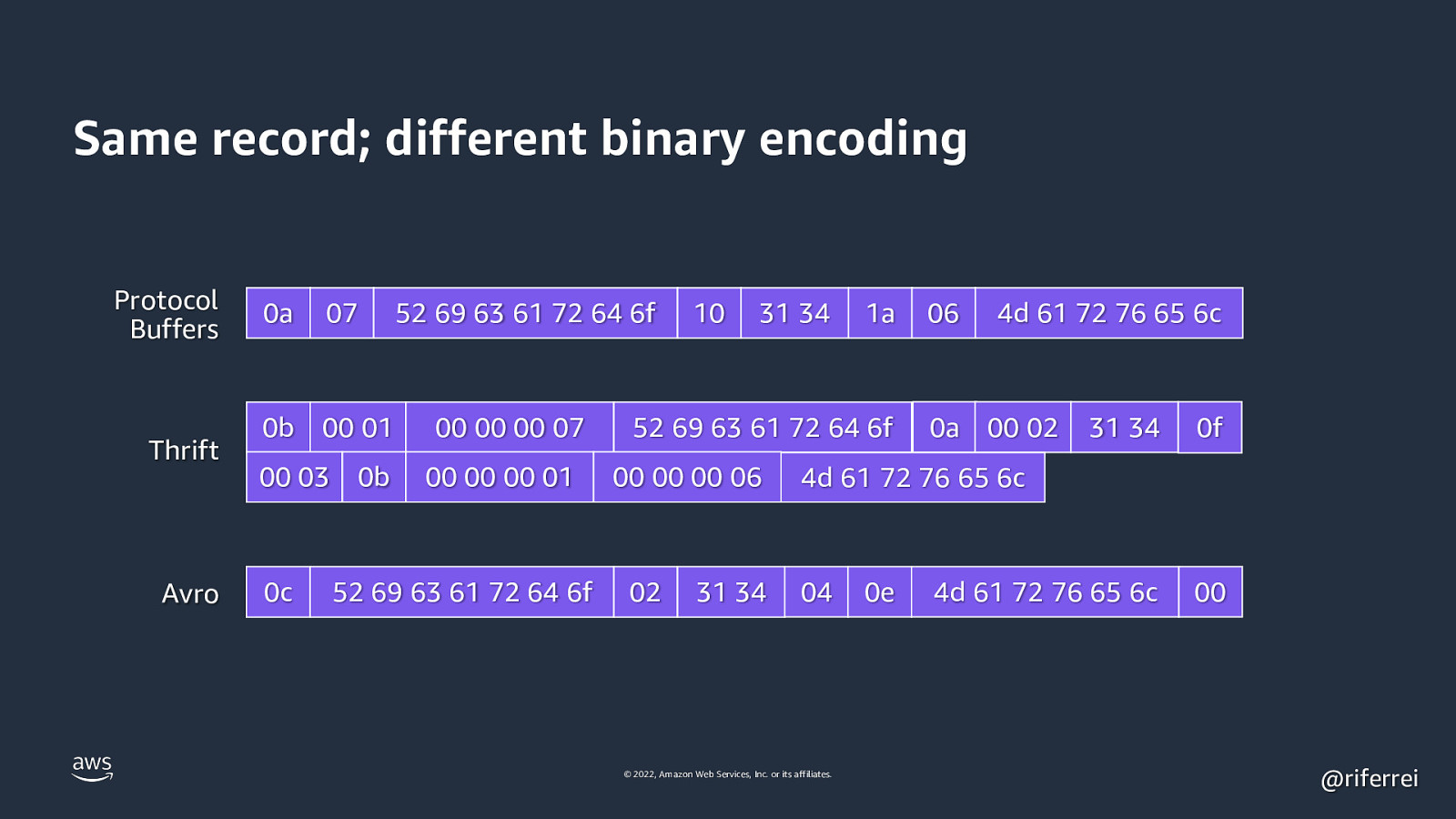
Same record; different binary encoding Protocol Buffers Thrift Avro 0a 07 0b 00 01 00 03 0c 52 69 63 61 72 64 6f 0b 00 00 00 07 00 00 00 01 52 69 63 61 72 64 6f 10 31 34 1a 06 52 69 63 61 72 64 6f 0a 00 00 00 06 02 31 34 4d 61 72 76 65 6c 00 02 31 34 0f 4d 61 72 76 65 6c 00 4d 61 72 76 65 6c 04 © 2022, Amazon Web Services, Inc. or its affiliates. 0e @riferrei

Schema compatibility • Backward compatibility: Newer code can read data from older code • Forward compatibility: Older code can read data from newer code © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
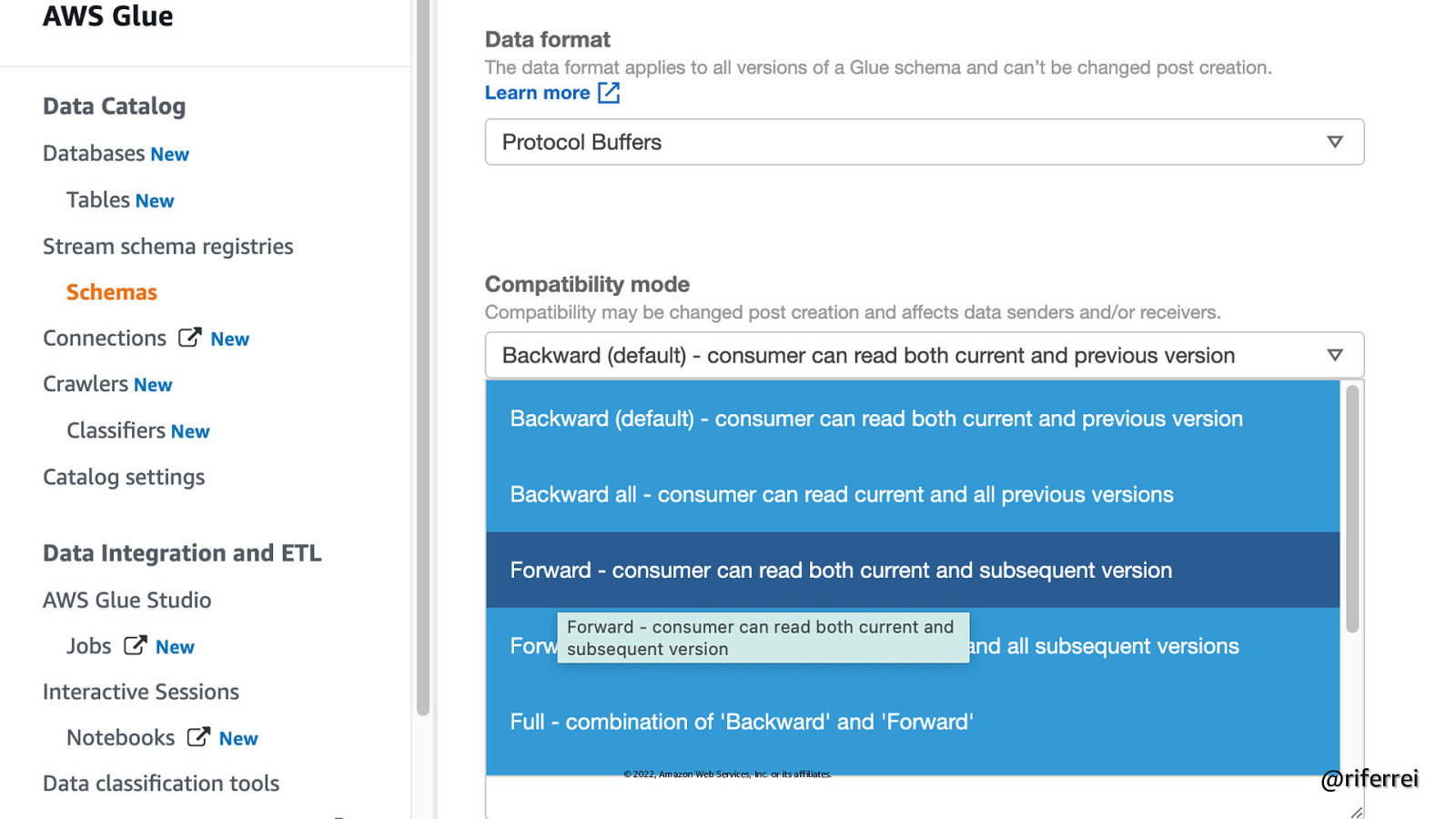
© 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Required/Optional fields • Not written into the binary format. • Used to provide runtime checks. • Useful to catching bugs in the code that writes data into the streams. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Schema evolution • Change field names, not the tags. • New fields must use new tags. • Old just code ignore unknown tags. • Datatype annotations help the parser to know how many bytes to skip when old code is reading new code. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Changing data types • Possible, but it may lose precision or get data being truncated. Read the documentation. • Change from single value to list depends on the binary format. • Protocol Buffers is just repeated in the format. It can be skipped. But Thrift requires data to be there. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Can I switch the Schema Registry to another registry? © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Time for 🧑💻 coding again • Scan the bar code in the right for the GitHub repository. • Each example has a unique number and a use case name. • In the folder that starts with “00-” you can find a Docker Compose file to spin up a Kafka deployment for testing. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Summary 1. Each programming language handles serialization differently. 2. Schema Registry is a database for schemas. It’s not Doctor Strange. 3. A record payload is not just the payload. Mind the Schema IDs. 4. Backward/forward compatibility is different in each binary format. 5. Migrating from one registry to another is possible. But not easy. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Chapter 4: Encoding and Evolution • Many thanks to Martin Kleppmann. • This chapter teaches all about code that can evolve using schemas. • This session is just a small portion of the chapter. I recommend you read the chapter in its entirety. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Thank you! Ricardo Ferreira @riferrei © 2022, Amazon Web Services, Inc. or its affiliates. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

One of the coolest things about streaming systems such as Apache Kafka is their ability to handle any type of data. You can store events at Kafka and have different systems processing their event data. You may start with a few systems and add new systems as needed. While certainly possible and attractive, this isn’t simple. Schemas play a key role in how each system consumes the event data and processes them. Reason Schema Registry exists, right? Not really. Schema Registry doesn’t solve any of your data problems. It’s just a registry for your schemas. Admittedly, without it, there would be no policy enforcement. However, data problems can still happen. Issues with encoding, format mismatch between different programming languages, new code not being able to read data written by old code, etc. In this session, we will get into the weeds of data serialization with schemas. We will discuss the differences between formats like JSON, Avro, Thrift, and Protocol Buffers, and how your code must use each one of them to serialize data. It will also clarify the impact of switching Schema Registry with other registries, and whether you can use them together. If you ever wondered why your Python code can’t read something written by Java, why integers are getting confused with strings, or simply how schemas end up in Schema Registry, this session is for you.
Code
The following code examples from the presentation can be tried out live.
Resources
The following resources were mentioned during the presentation or are useful additional information.
Buzz and feedback
Here’s what was said about this presentation on social media.