In the land of the sizing, the one-partition Kafka topic is king
A presentation at Strange Loop 2022 in in St. Louis, MO, USA by Ricardo Ferreira

In the land of the sizing, the one-partition Kafka topic is king Ricardo Ferreira Senior Developer Advocate Amazon Web Services © 2022, Amazon Web Services, Inc. or its affiliates. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

“Partitions are only relevant for high-load scenarios. They allow for parallel processing.” — every developer in the world © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

© 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

© 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

In reality, Kafka partitions are: 1. Unit-Of-Storage 2. Unit-Of-Parallelism © 2022, Amazon Web Services, Inc. or its affiliates. 3. Unit-Of-Durability @riferrei

Partitions as the unit-of-storage © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
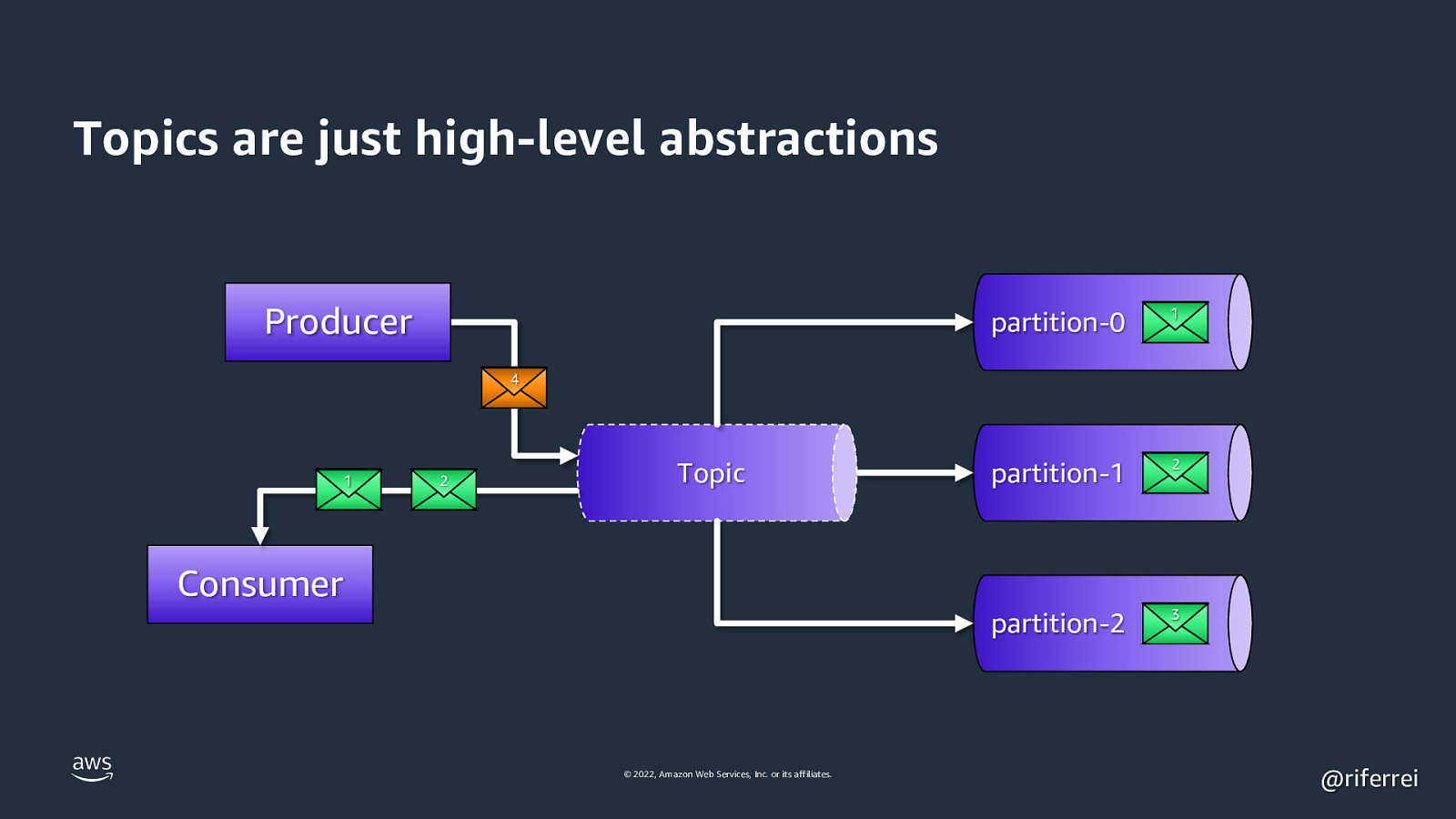
Topics are just high-level abstractions Producer partition-0 1 partition-1 2 partition-2 3 4 1 2 Topic Consumer © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Partitions and segments Segment 0 (1GB) partition-0 Segment 1 (1GB) Segment 0 (1GB) partition-1 Segment 1 (1GB) © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Segments and file handles File Handle File Handle © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Quiz time: • One broker with 1024 file handles. • One topic with only one partition. • Producer writes data every minute. • Each write holds 250MB of data. What is going to happen? 🤔 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Result: In 48 hours, this broker will run out of file handles and crash. Because each log segment grow up to 1GB. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
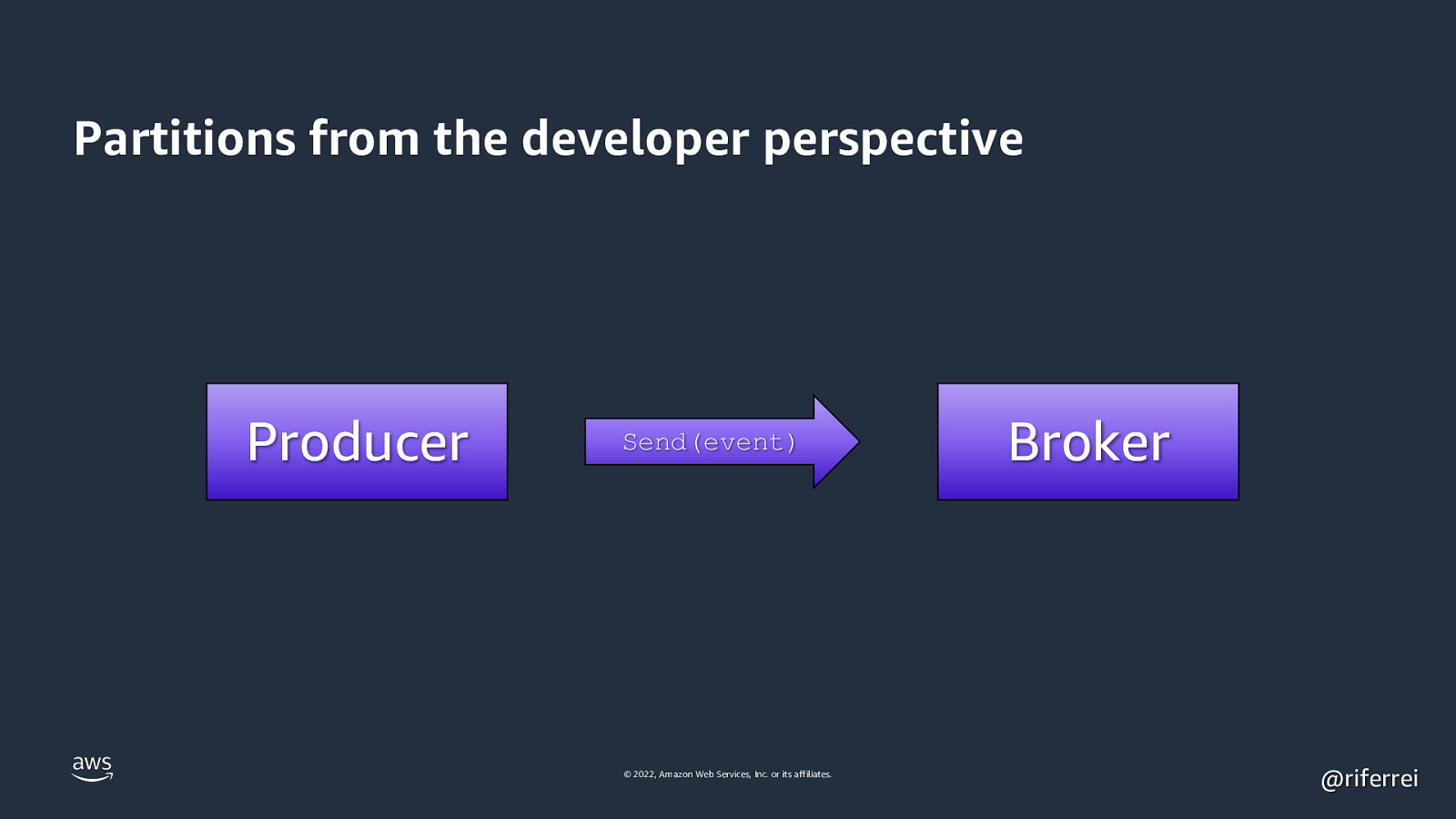
Partitions from the developer perspective Producer Send(event) © 2022, Amazon Web Services, Inc. or its affiliates. Broker @riferrei

KIP-794: How partitioning works 1. Partition set If the event has an partition set, then it goes to that partition. 2. Partitioner.class Otherwise it is based on the logic from the configured partitioner. 3. Using keys Otherwise it will use the assigned key to figure the partition. © 2022, Amazon Web Services, Inc. or its affiliates. 4. Broker load Last fallback is based on factors like broker load, amount of data produced to each partition, etc. @riferrei
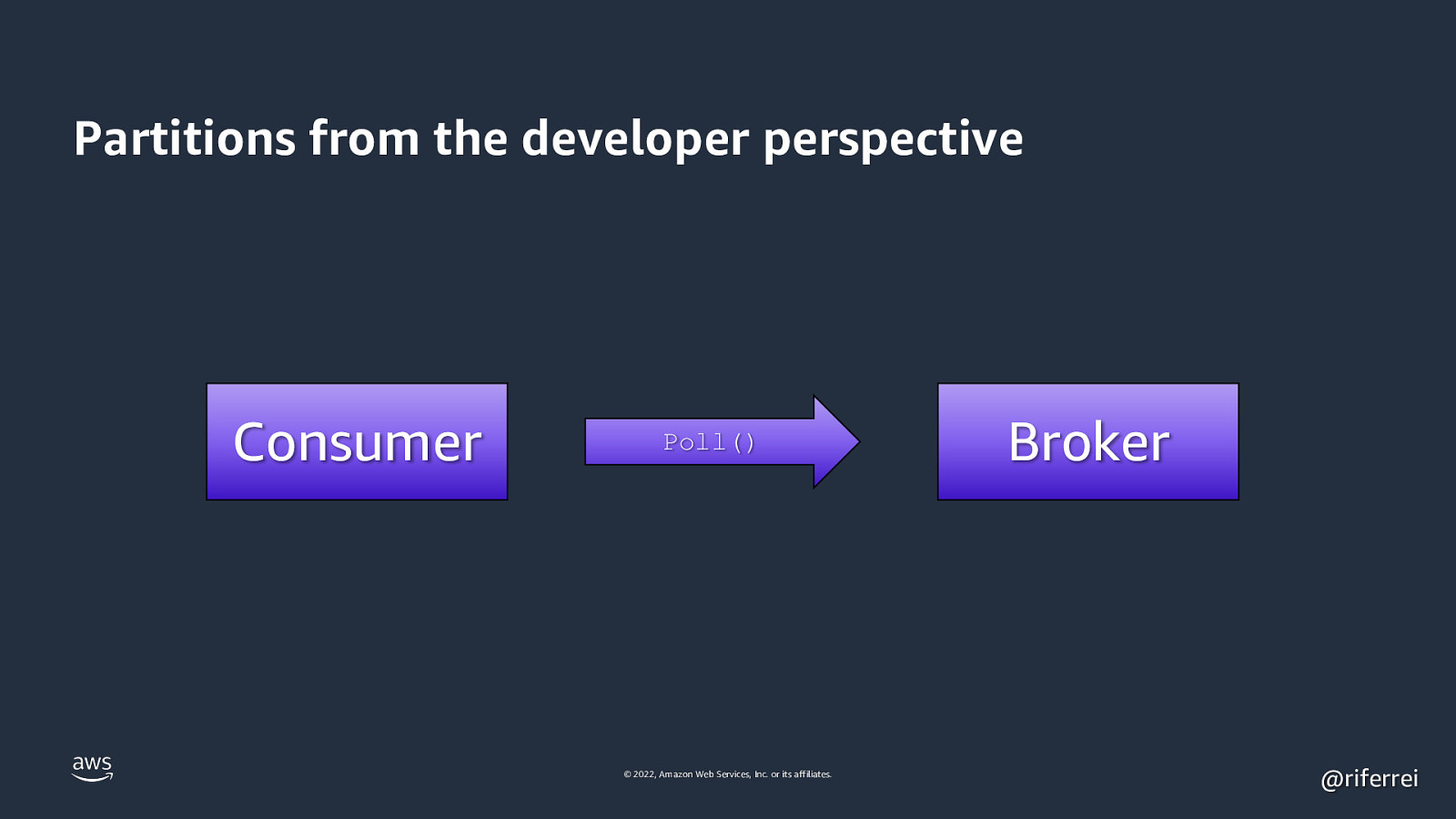
Partitions from the developer perspective Consumer Poll() © 2022, Amazon Web Services, Inc. or its affiliates. Broker @riferrei
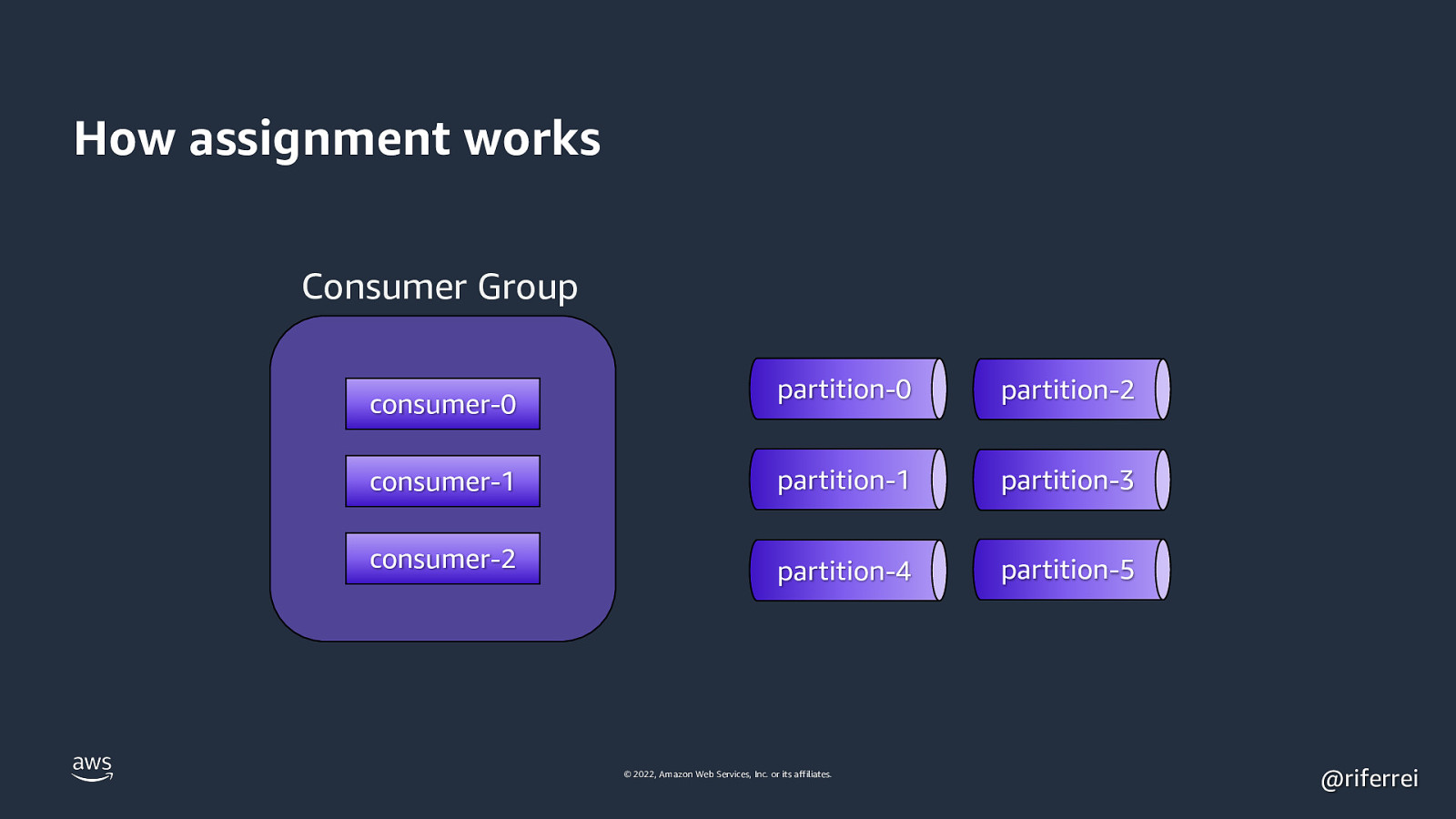
How assignment works Consumer Group partition-0 partition-2 consumer-1 partition-1 partition-3 consumer-2 partition-4 partition-5 consumer-0 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
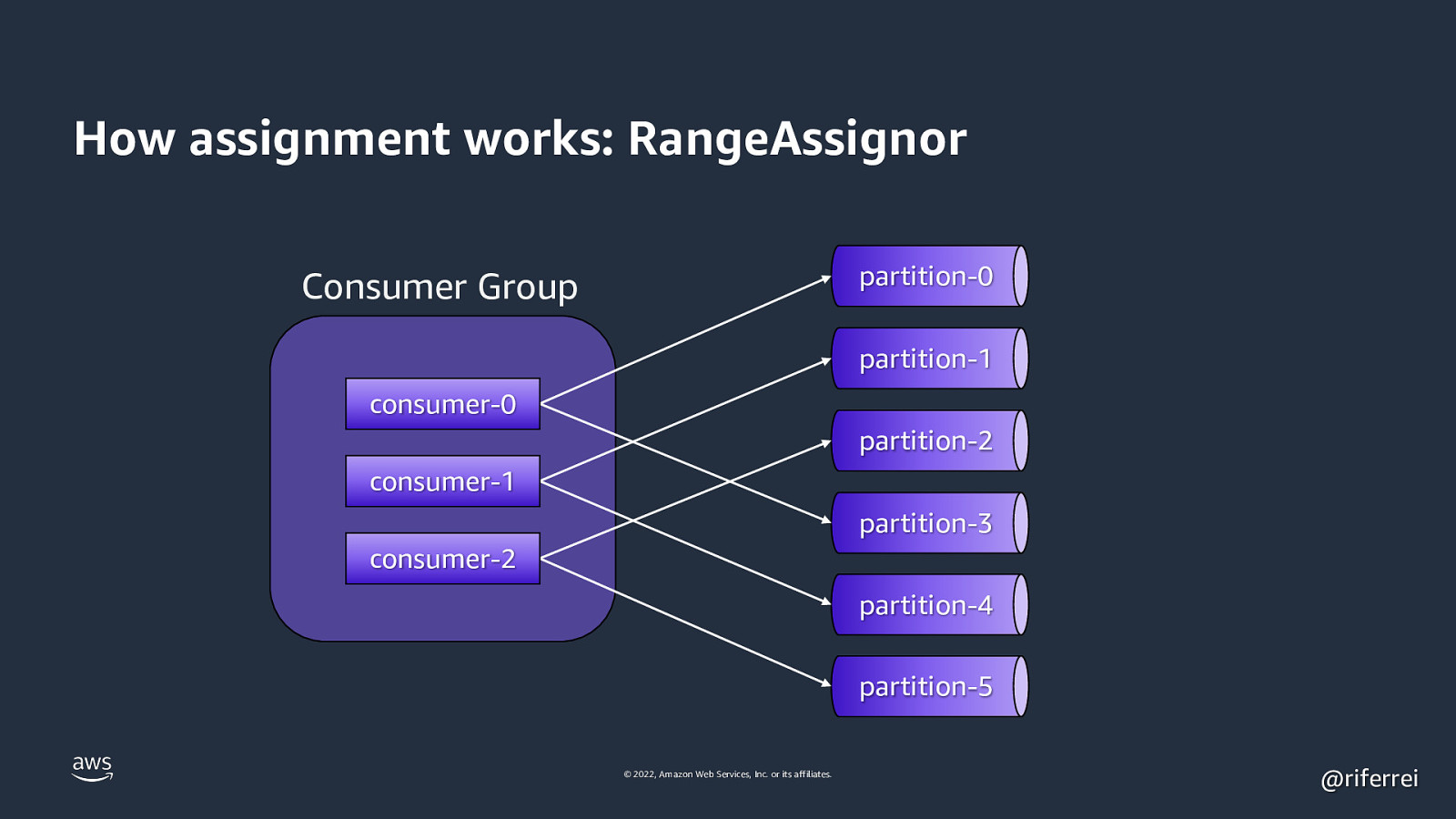
How assignment works: RangeAssignor partition-0 Consumer Group partition-1 consumer-0 partition-2 consumer-1 partition-3 consumer-2 partition-4 partition-5 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Quiz time: • Single topic with 6 partitions. • Consumer group with 3 consumers. • RangeAssignor is being used. • One of the consumers dies. What is going to happen? 🤔 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Result: The remaining 2 consumers will stop processing events until all partitions are reassigned. This problem is known as stop-theworld pauses. Reason why you must used the CooperativeStickyAssignor as much as possible for new Kafka clusters. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
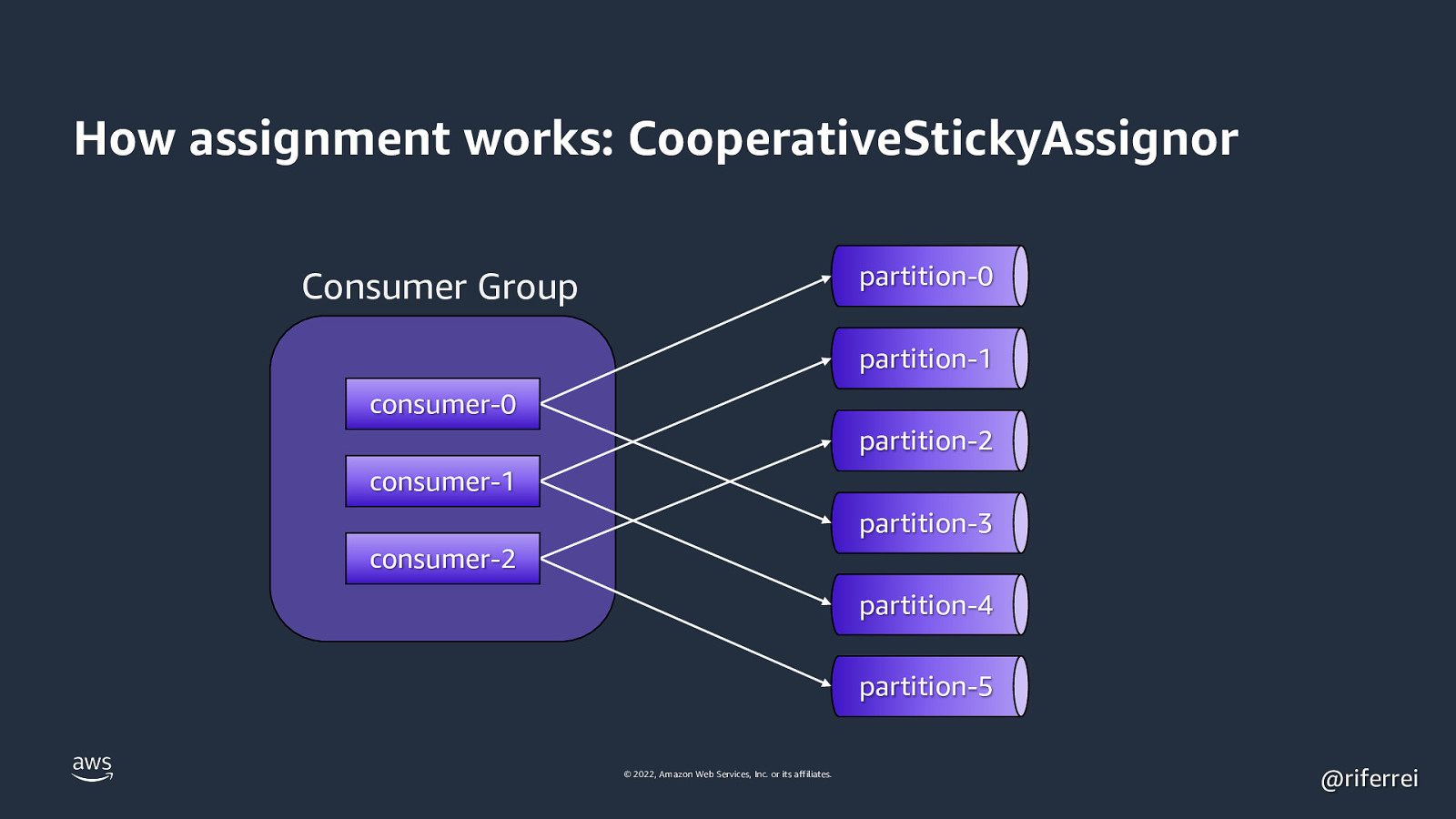
How assignment works: CooperativeStickyAssignor partition-0 Consumer Group partition-1 consumer-0 partition-2 consumer-1 partition-3 consumer-2 partition-4 partition-5 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
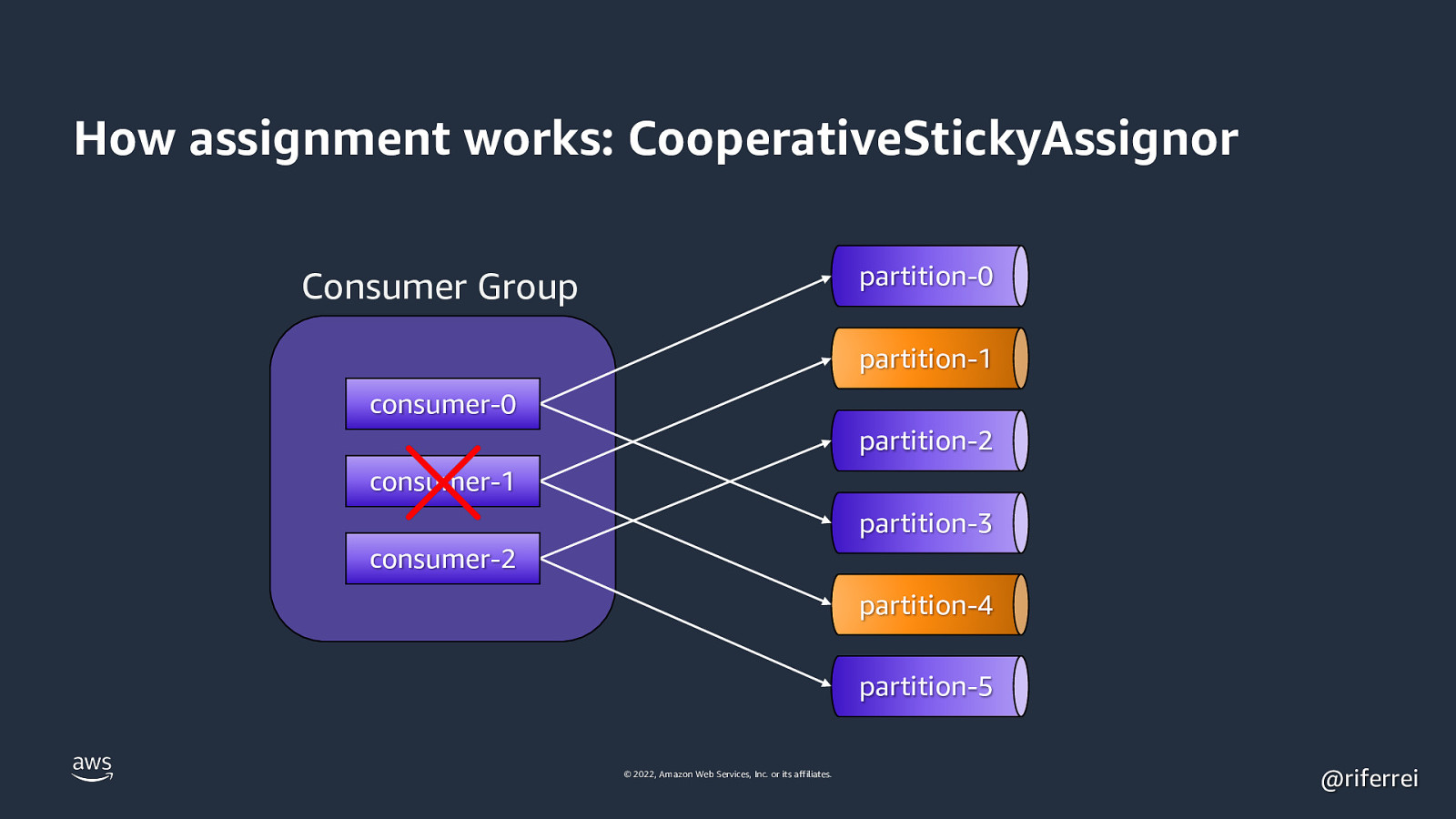
How assignment works: CooperativeStickyAssignor partition-0 Consumer Group partition-1 consumer-0 partition-2 consumer-1 partition-3 consumer-2 partition-4 partition-5 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
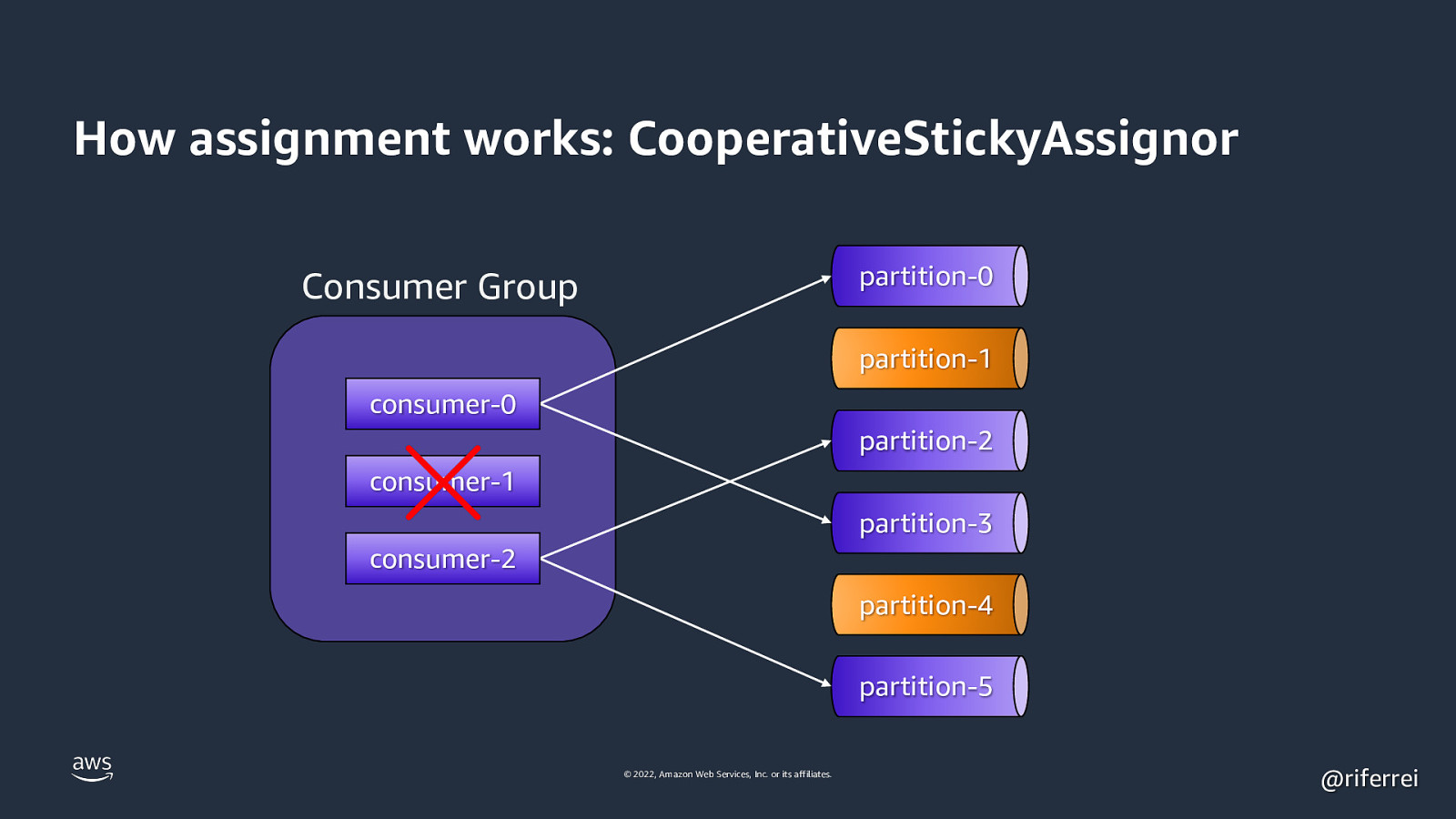
How assignment works: CooperativeStickyAssignor partition-0 Consumer Group partition-1 consumer-0 partition-2 consumer-1 partition-3 consumer-2 partition-4 partition-5 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
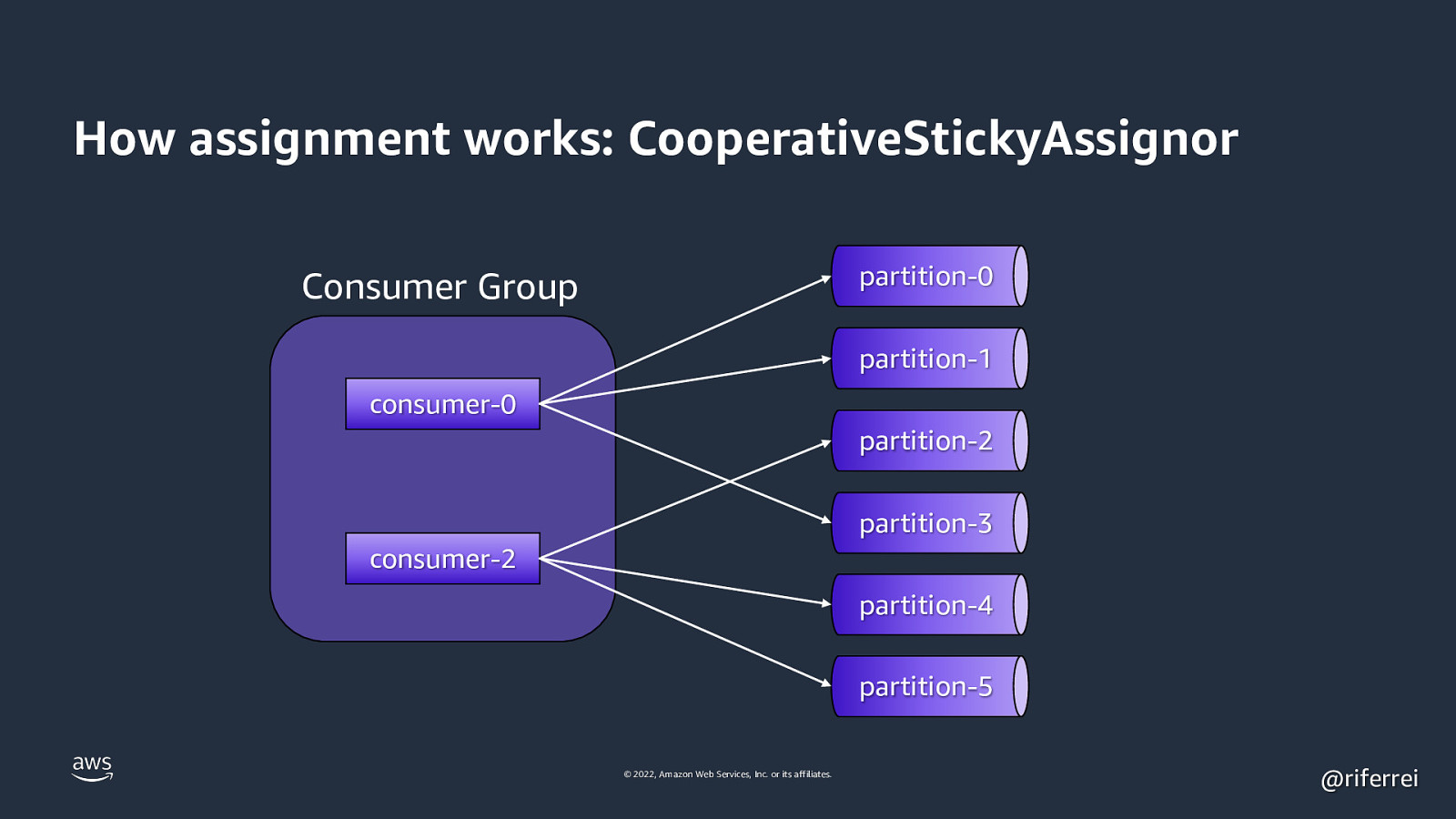
How assignment works: CooperativeStickyAssignor partition-0 Consumer Group partition-1 consumer-0 partition-2 partition-3 consumer-2 partition-4 partition-5 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
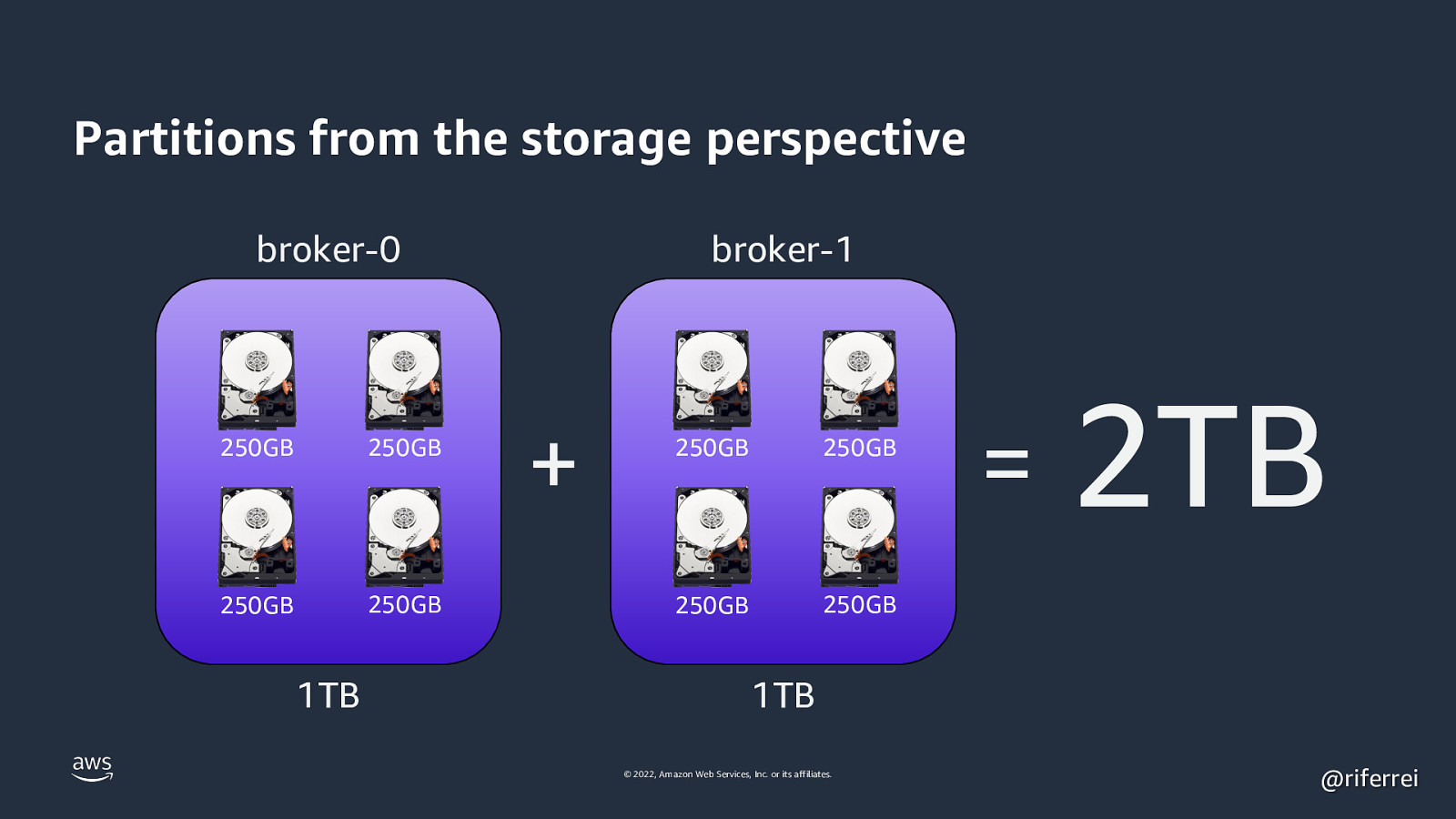
Partitions from the storage perspective broker-0 250GB 250GB 250GB 250GB 1TB broker-1 + 250GB 250GB 250GB 250GB
2TB 1TB © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Quiz time: • Single cluster with 2 brokers. • One topic with 4 partitions. How partitions are distributed? 🤔 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
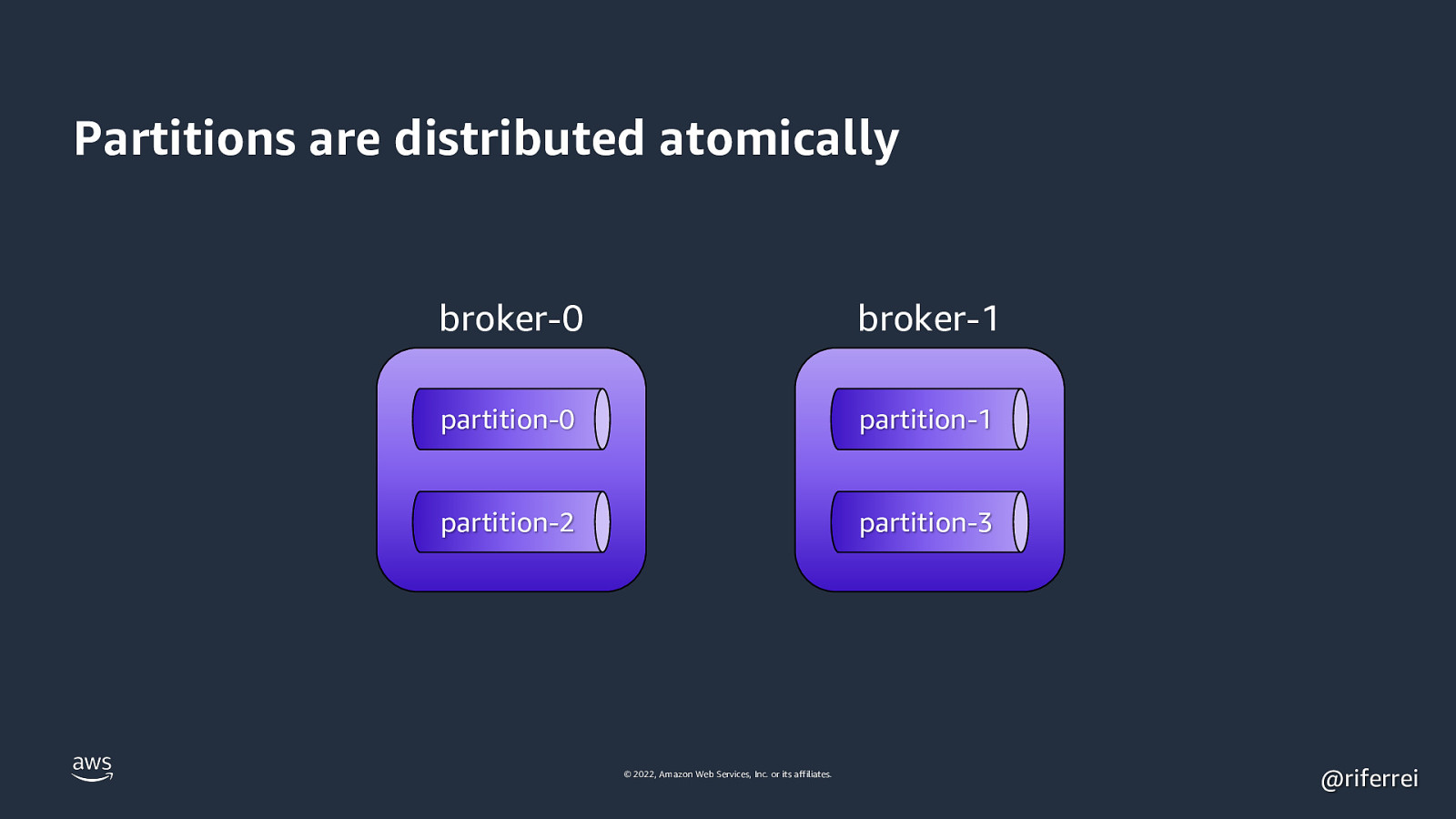
Partitions are distributed atomically broker-0 broker-1 partition-0 partition-1 partition-2 partition-3 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Quiz time: • Single cluster with 2 brokers. • One topic with 4 partitions. • You add more 2 brokers. How partitions are distributed? 🤔 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Result: There is no distribution. The partitions will be sitting in the first two brokers. Partitions are not automatically reassigned as you add new brokers. You have to do this manually. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
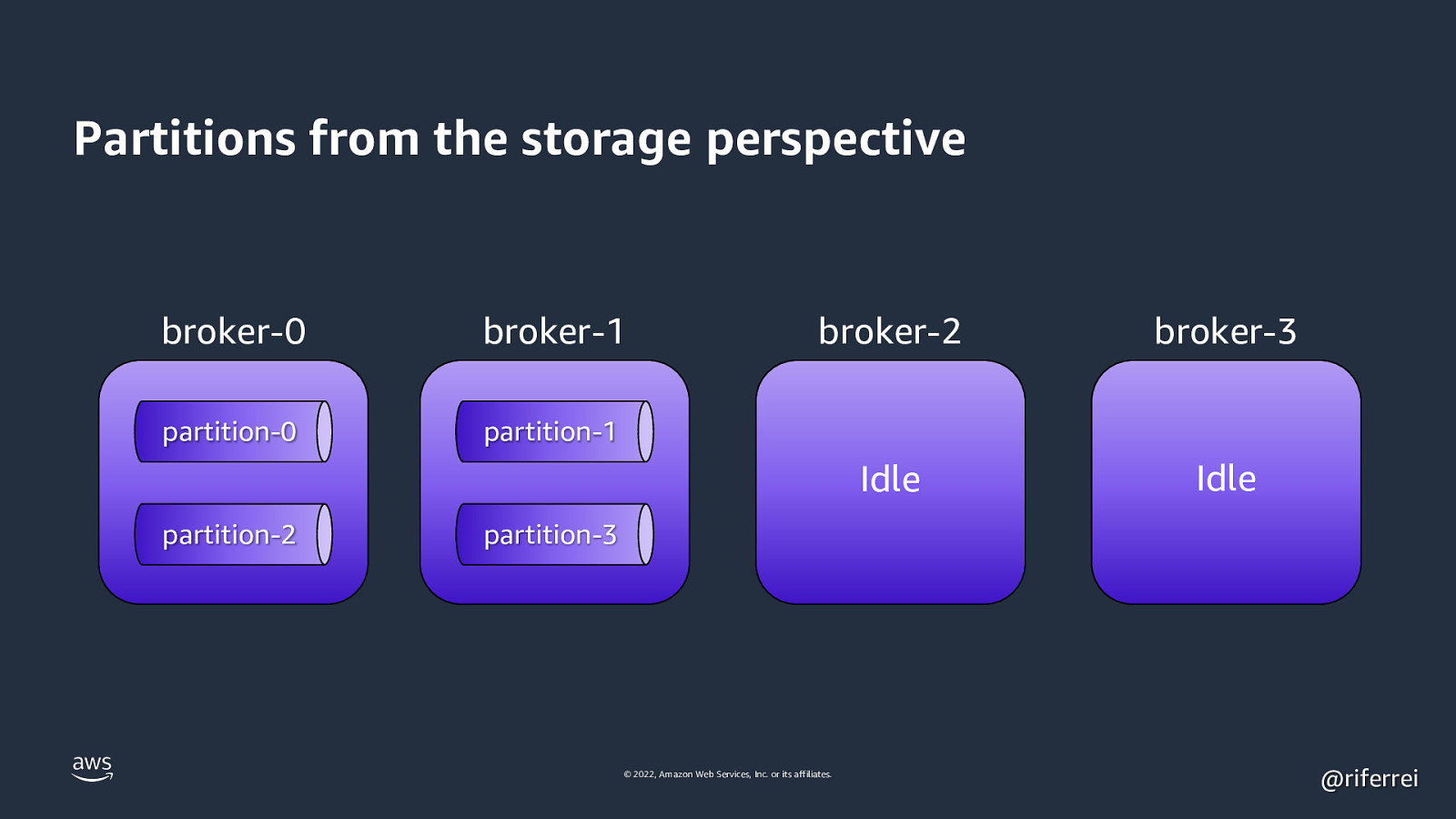
Partitions from the storage perspective broker-0 broker-1 partition-0 partition-1 partition-2 broker-2 broker-3 Idle Idle partition-3 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

How to reassign the partitions? 1. Bounce the entire cluster: leads to unavailability but once its back the partitions are reassigned. 2. kafka-reassign-partitions: CLI tool you where you can reassign the partitions with the cluster online. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Demo time! © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Partitions as the unit-of-parallelism © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Understanding read throughput issues Producer Broker Consumer Throughput in events/sec Disk I/O and Network I/O Throughput in events/sec © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

“Consumers in Kafka are simple. You just need to continuously poll events from the topics.” © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
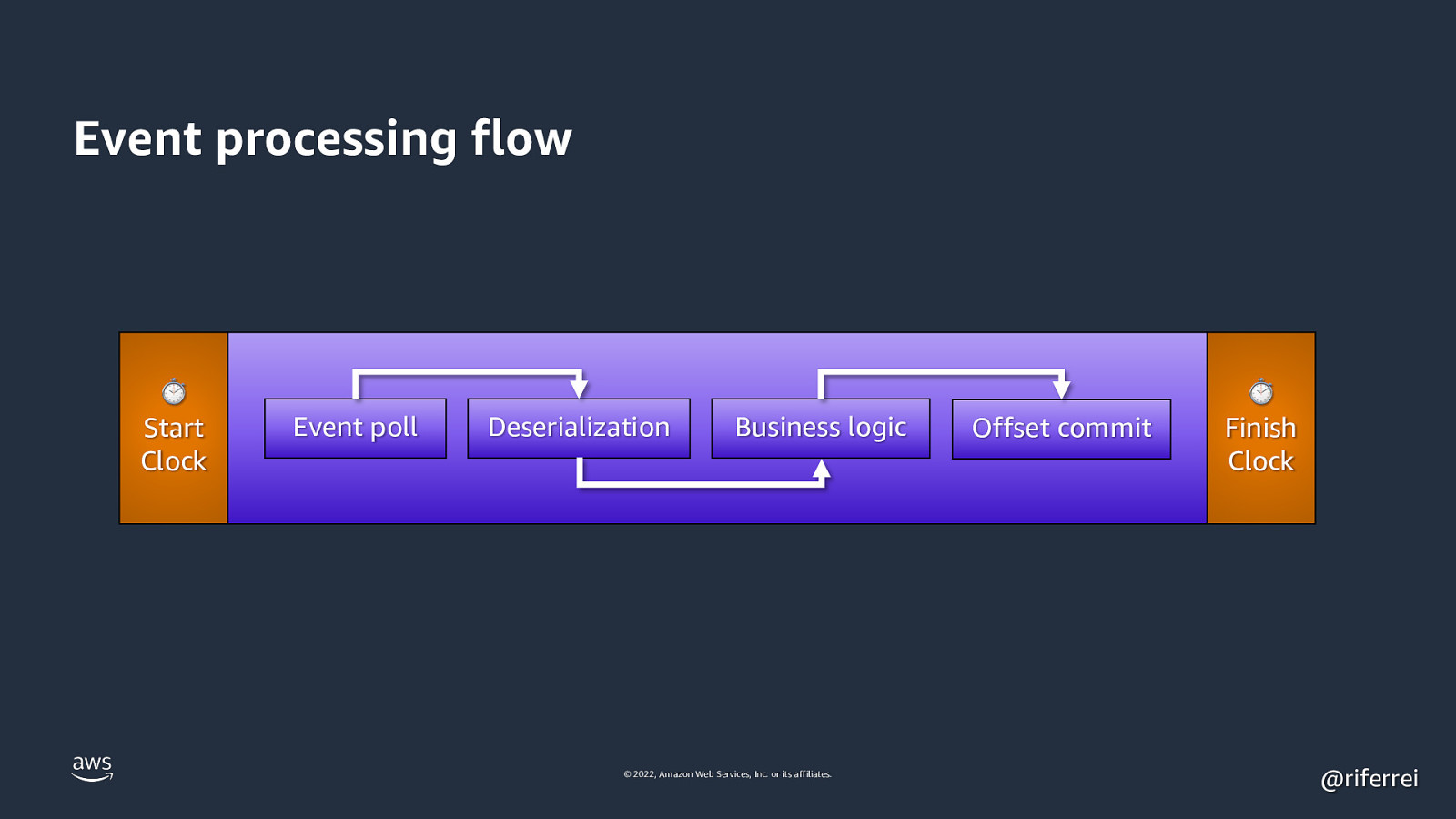
Event processing flow ⏱ Start Clock Event poll Deserialization Business logic © 2022, Amazon Web Services, Inc. or its affiliates. Offset commit ⏱ Finish Clock @riferrei
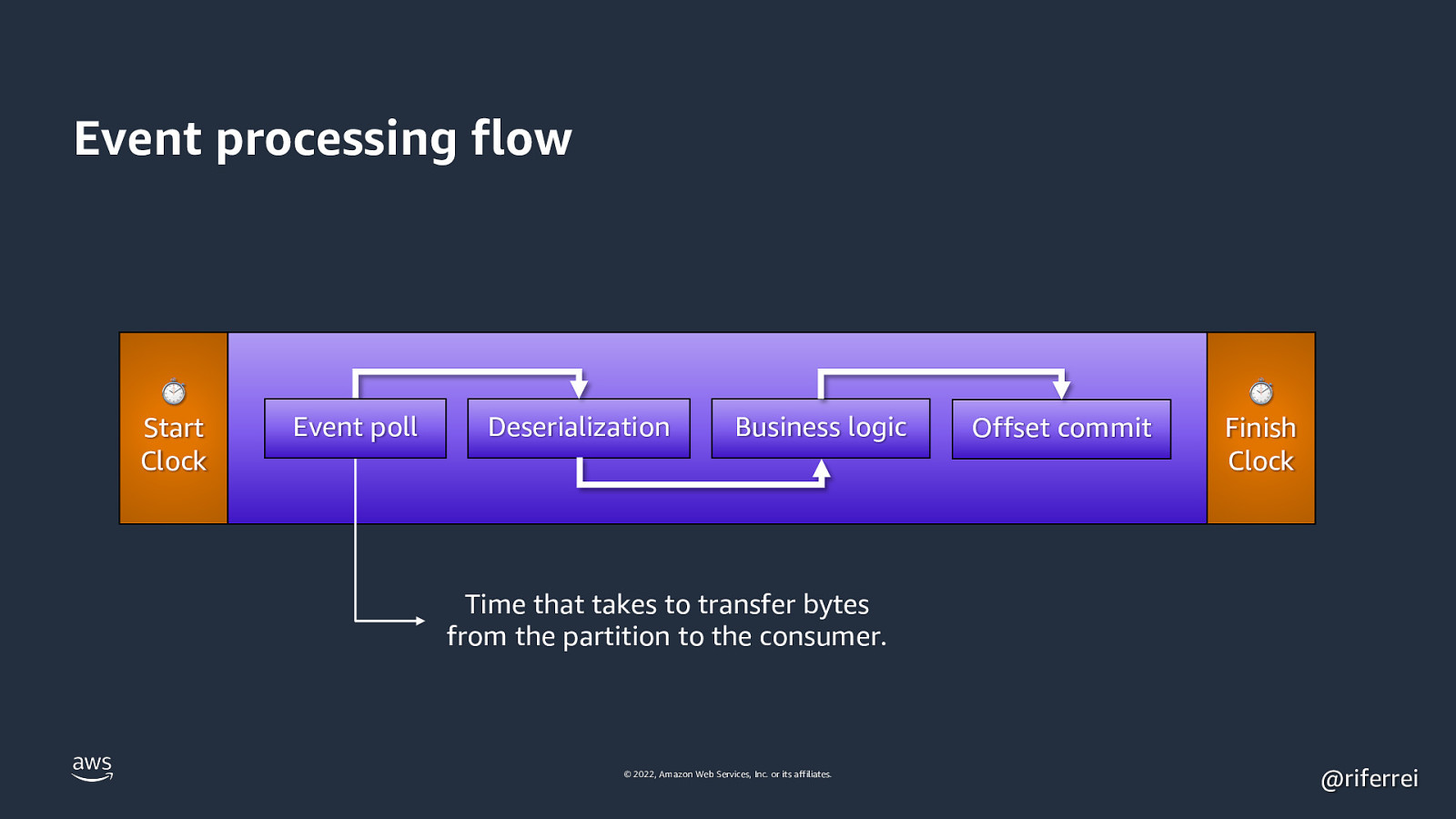
Event processing flow ⏱ Start Clock Event poll Deserialization Business logic Offset commit ⏱ Finish Clock Time that takes to transfer bytes from the partition to the consumer. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
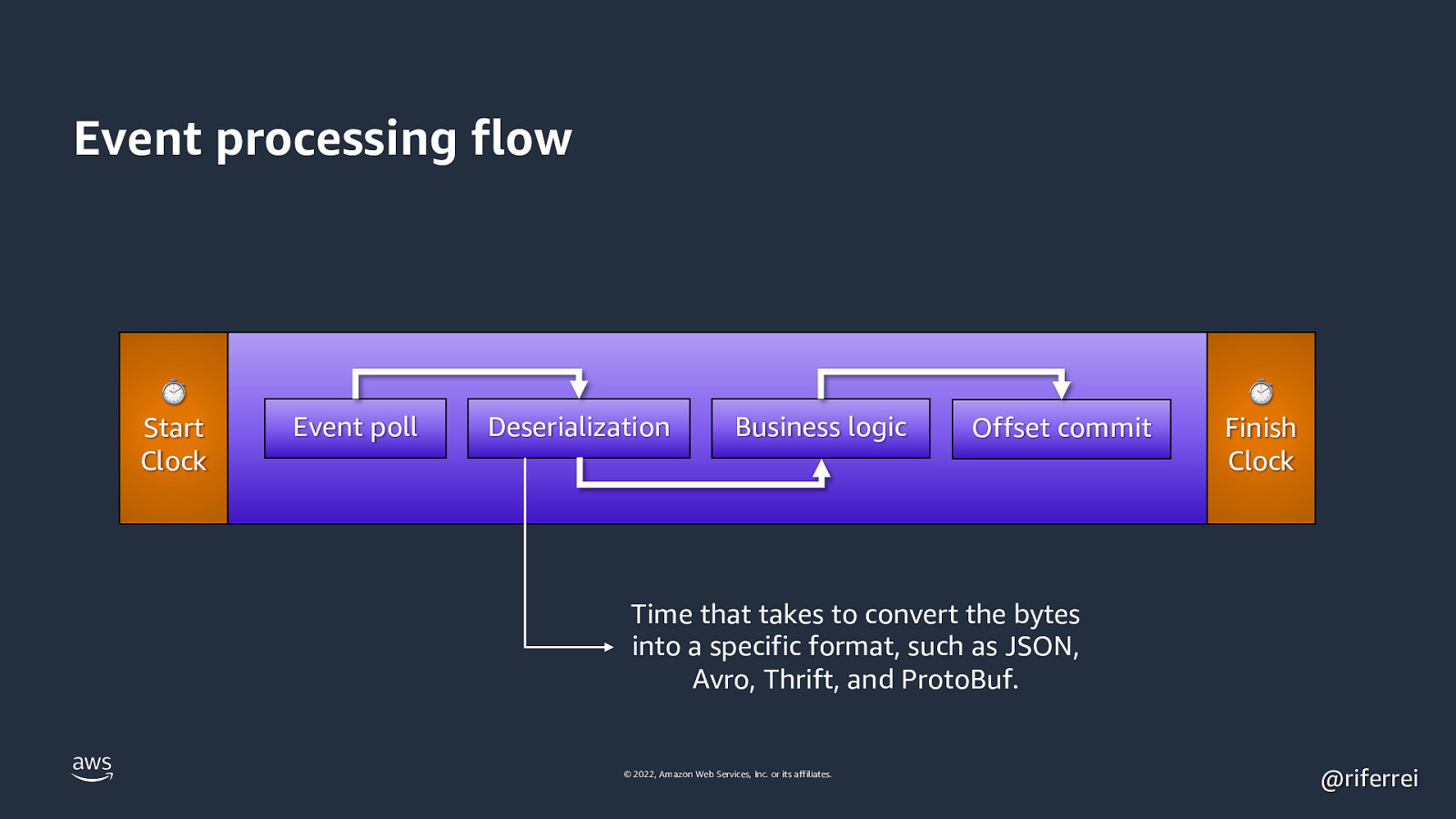
Event processing flow ⏱ Start Clock Event poll Deserialization Business logic Offset commit ⏱ Finish Clock Time that takes to convert the bytes into a specific format, such as JSON, Avro, Thrift, and ProtoBuf. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
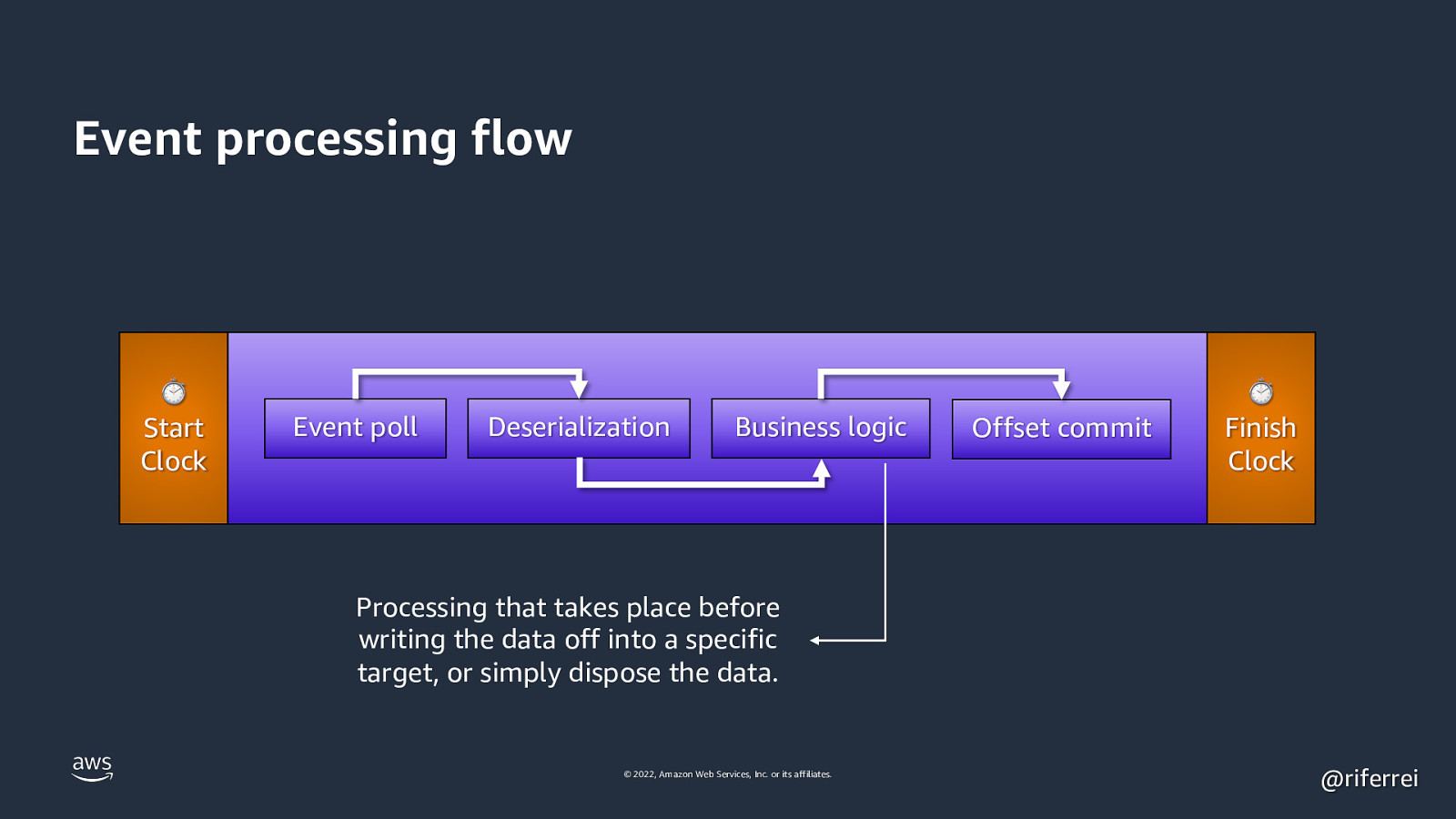
Event processing flow ⏱ Start Clock Event poll Deserialization Business logic Offset commit ⏱ Finish Clock Processing that takes place before writing the data off into a specific target, or simply dispose the data. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
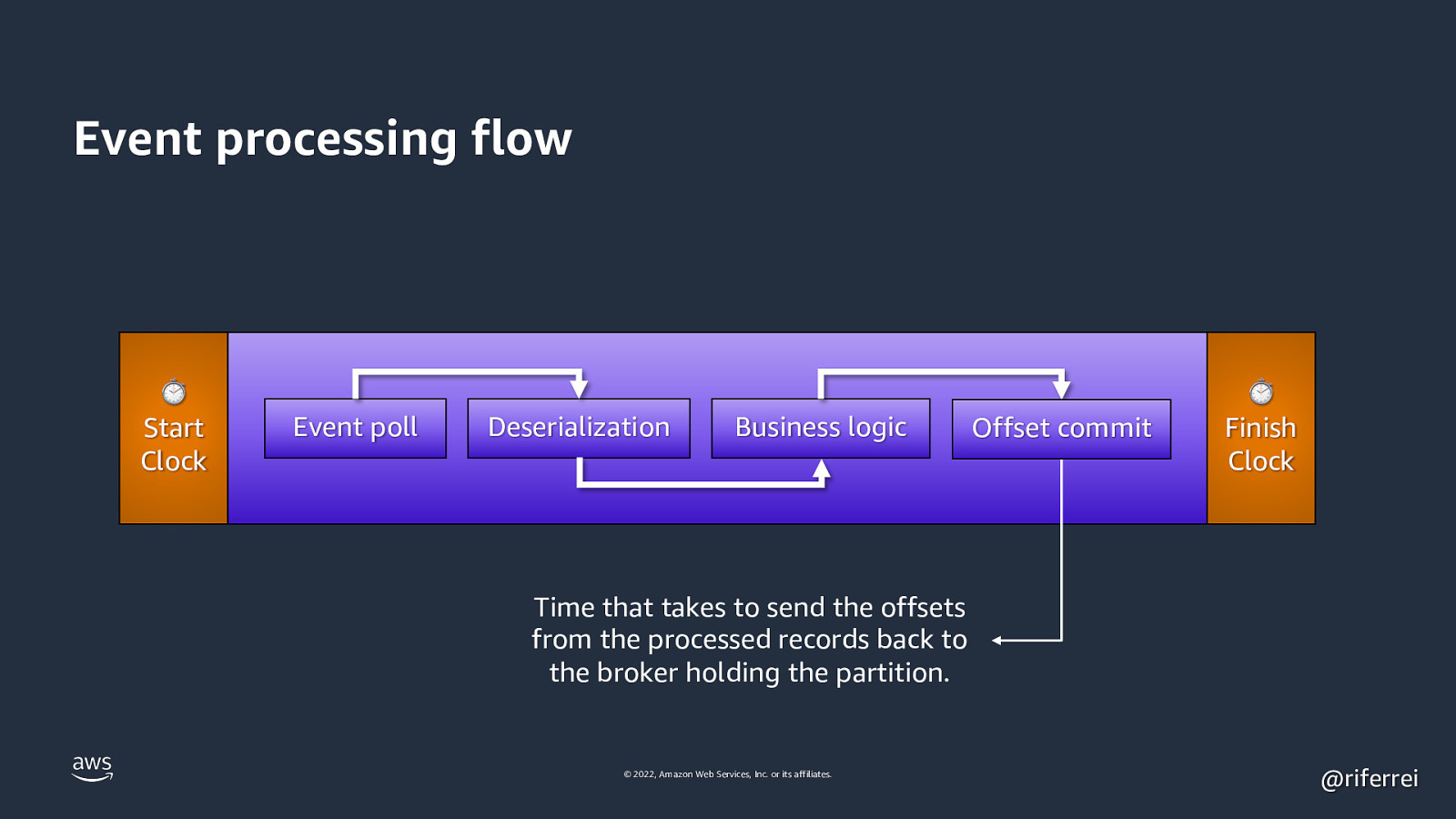
Event processing flow ⏱ Start Clock Event poll Deserialization Business logic Offset commit ⏱ Finish Clock Time that takes to send the offsets from the processed records back to the broker holding the partition. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
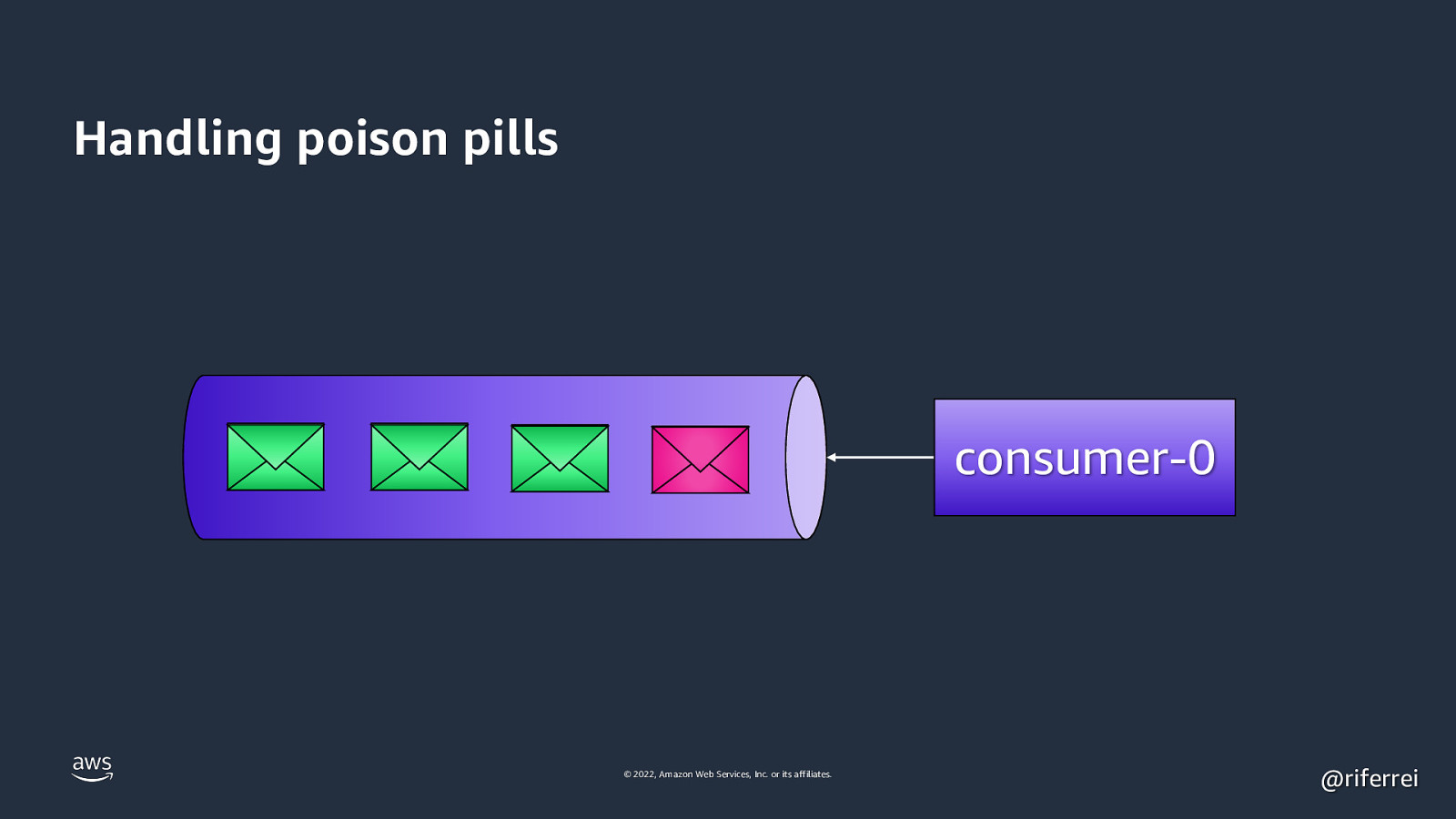
Handling poison pills poll © 2022, Amazon Web Services, Inc. or its affiliates. consumer-0 @riferrei

Quiz time: • One topic with 1 partition. • 100 messages waiting processing. • 5 last messages are poison pills. • Consumer with default config. How many messages committed? 🤔 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Result: No one knows. By default Kafka auto commit the messages in a interval. If the poison pill raises an exception, the the polling will break and stop the committing. If not, then congrats: you got yourself a integrity issue problem. For use cases with integrity semantics, you have to manually commit the offsets in a per-message basis. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

The event poll loop while(true) { ConsumerRecords records = consumer.poll(Duration.ofMillis(10000)); processRetrievedRecords(records); } © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
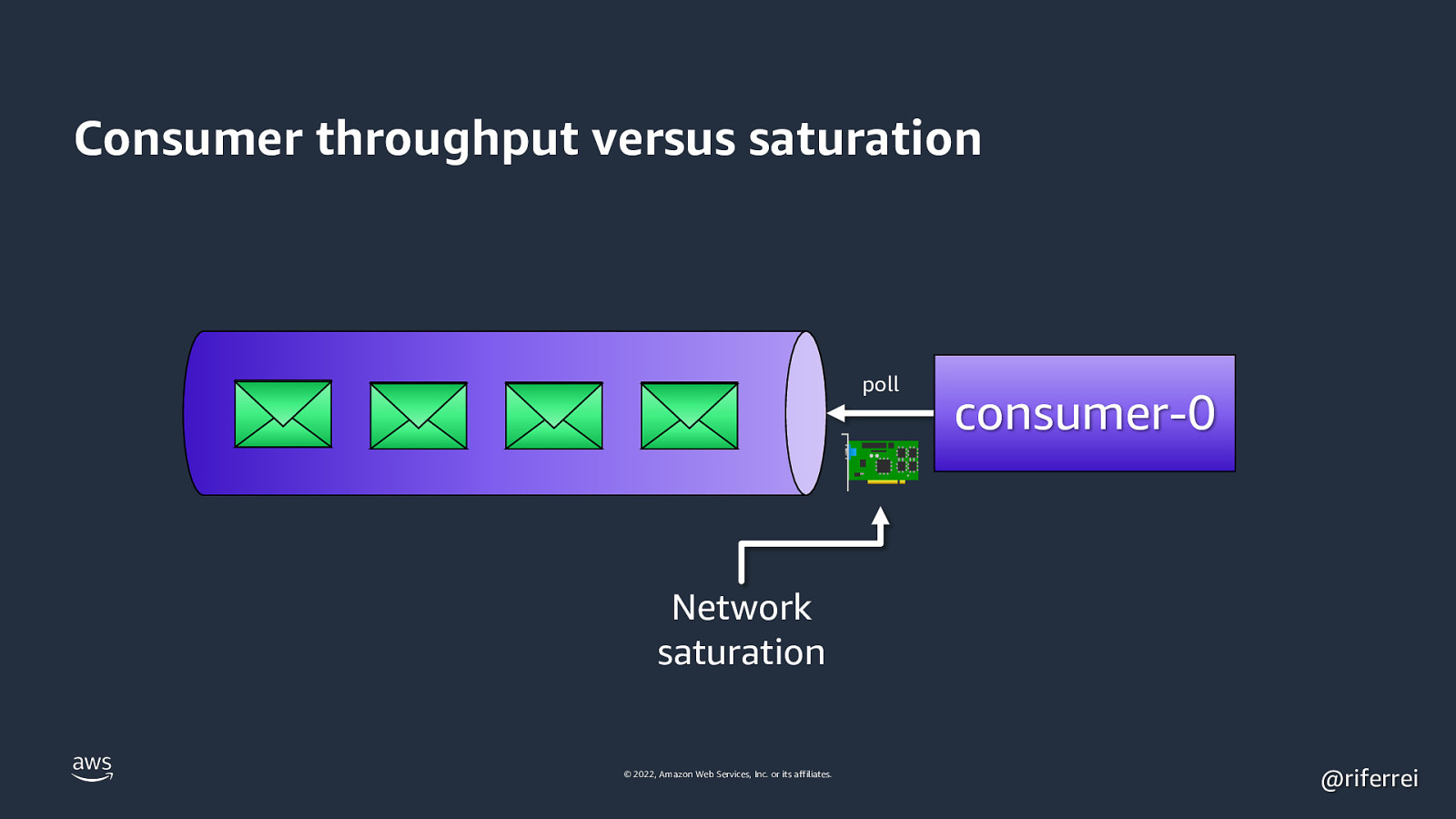
Consumer throughput versus saturation 10,000 poll consumer-0 events/sec Network saturation © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
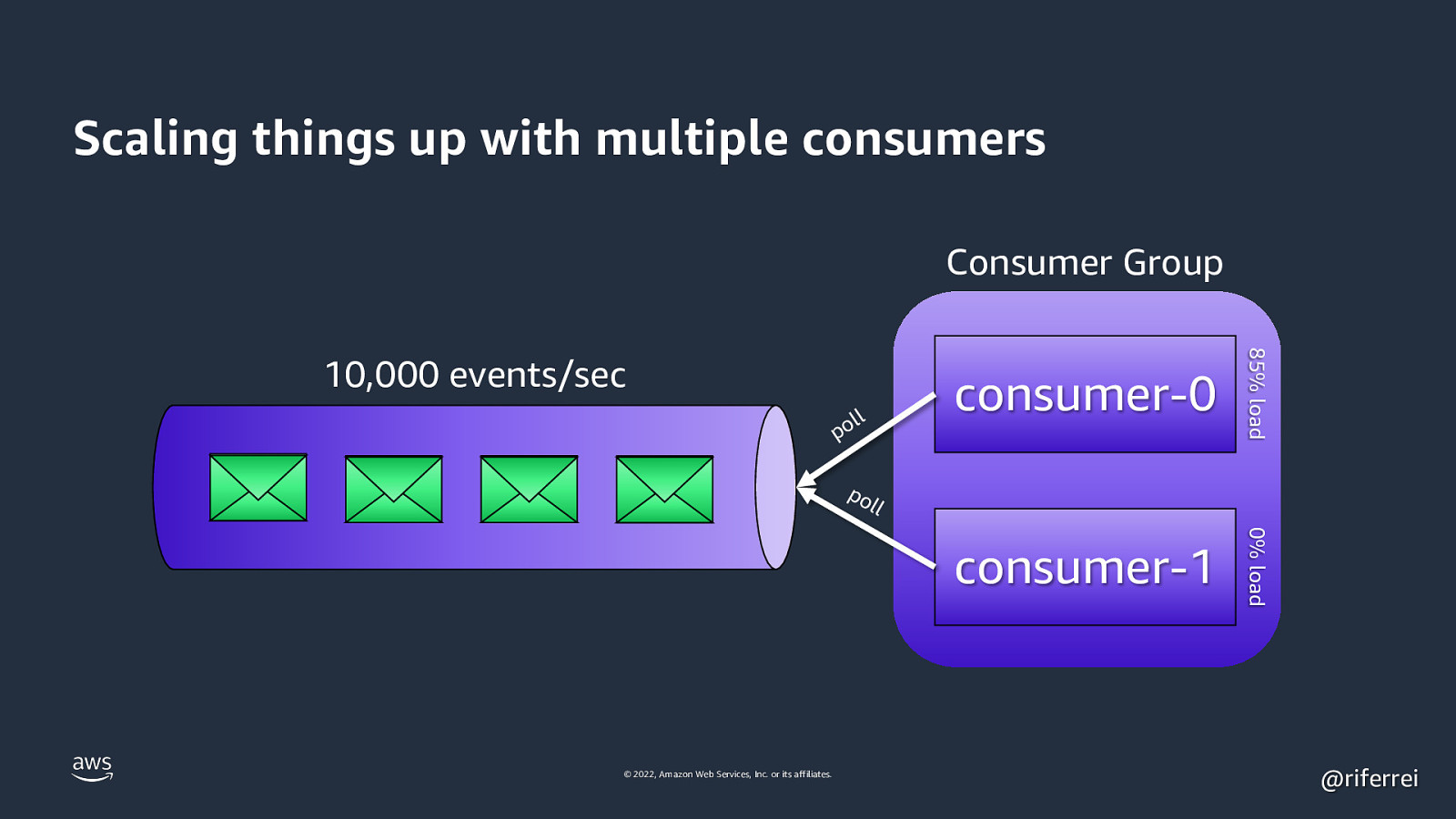
Scaling things up with multiple consumers Consumer Group consumer-0 consumer-1 0% load ll po 85% load 10,000 events/sec po ll © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Quiz time: • One topic with 1 partition. • 2 consumers in different nodes. • Consumers in different groups. Can throughput be doubled? 🤔 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Result: No. Putting different consumers in different groups will tell Kafka to broadcast the same message to the groups, leading to a serious problem of data consistency. If you need true parallelism, then you need to have dedicated partitions to each group. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
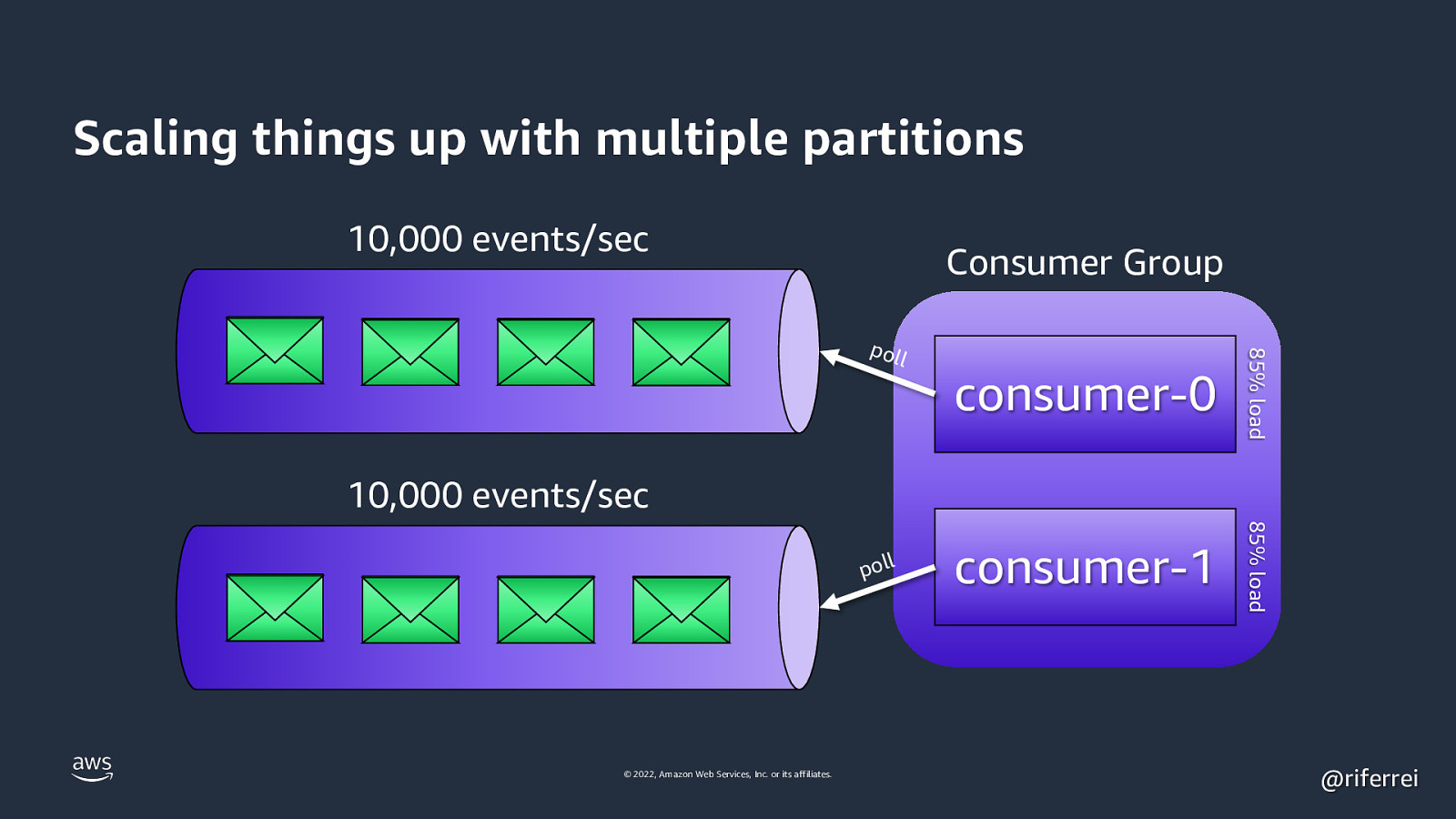
Scaling things up with multiple partitions 10,000 events/sec Consumer Group consumer-0 85% load consumer-1 85% load poll 10,000 events/sec poll © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

How many partitions to create? © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
© 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Good “good enough” method: NUM_PARTITIONS = MAX(T/W, T/R) T = Target throughput in events/second W = Write throughput in events/second R = Read throughput in events/second © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Okay, but how to measure W and R? © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Demo time! © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Keep mind extra processing time ⏱ Start Clock Event poll Deserialization Business logic © 2022, Amazon Web Services, Inc. or its affiliates. Offset commit ⏱ Finish Clock @riferrei

Partitions as the unit-of-durability © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
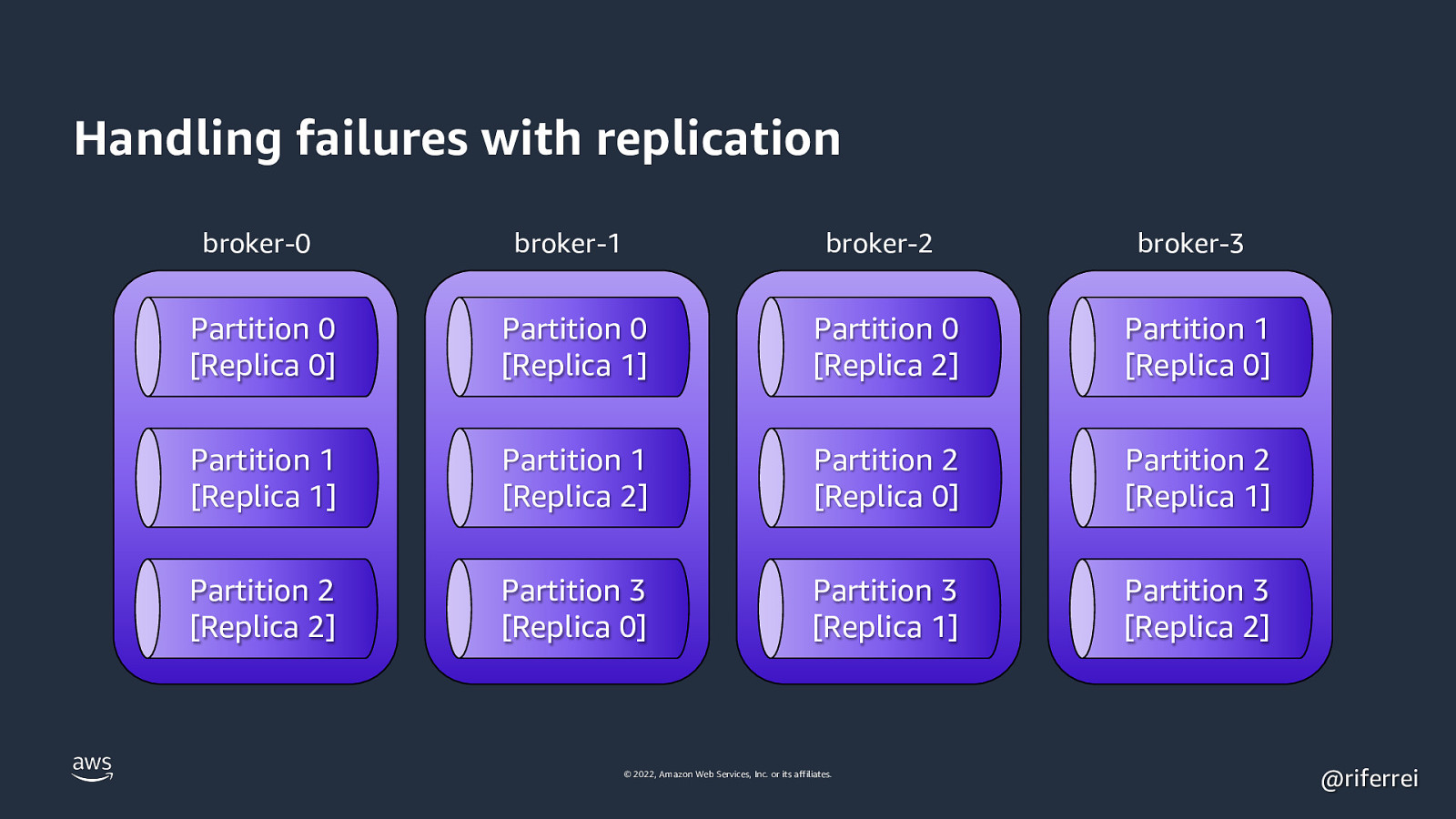
Handling failures with replication broker-0 broker-1 broker-2 broker-3 Partition 0 [Replica 0] Partition 0 [Replica 1] Partition 0 [Replica 2] Partition 1 [Replica 0] Partition 1 [Replica 1] Partition 1 [Replica 2] Partition 2 [Replica 0] Partition 2 [Replica 1] Partition 2 [Replica 2] Partition 3 [Replica 0] Partition 3 [Replica 1] Partition 3 [Replica 2] © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei
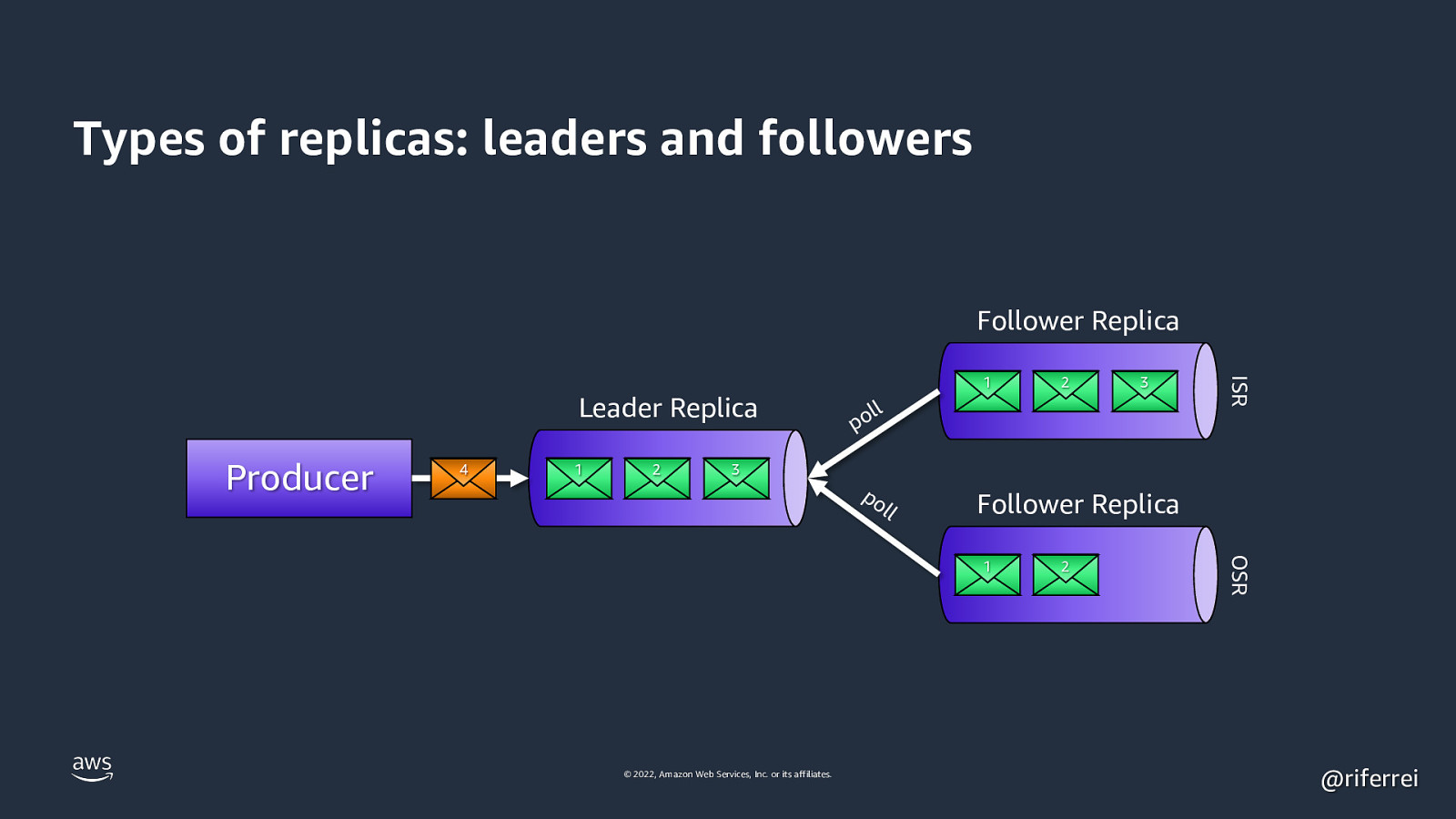
Types of replicas: leaders and followers Follower Replica Producer 4 1 2 2 3 ll po ISR Leader Replica 1 3 po l l Follower Replica © 2022, Amazon Web Services, Inc. or its affiliates. 2 OSR 1 @riferrei
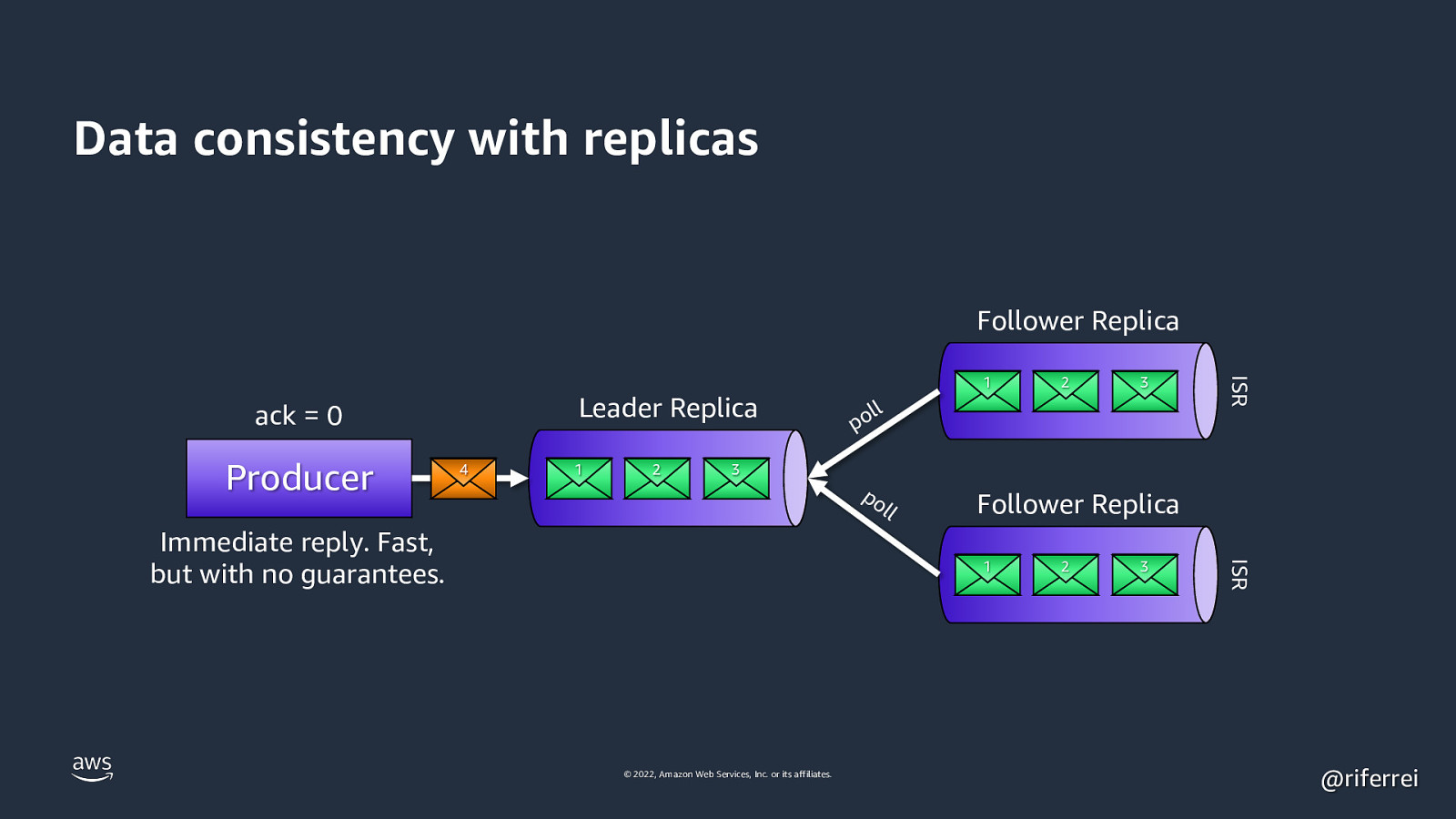
Data consistency with replicas Follower Replica Producer 4 1 2 2 3 ll po ISR Leader Replica ack = 0 1 3 po l Follower Replica 1 © 2022, Amazon Web Services, Inc. or its affiliates. 2 3 ISR Immediate reply. Fast, but with no guarantees. l @riferrei
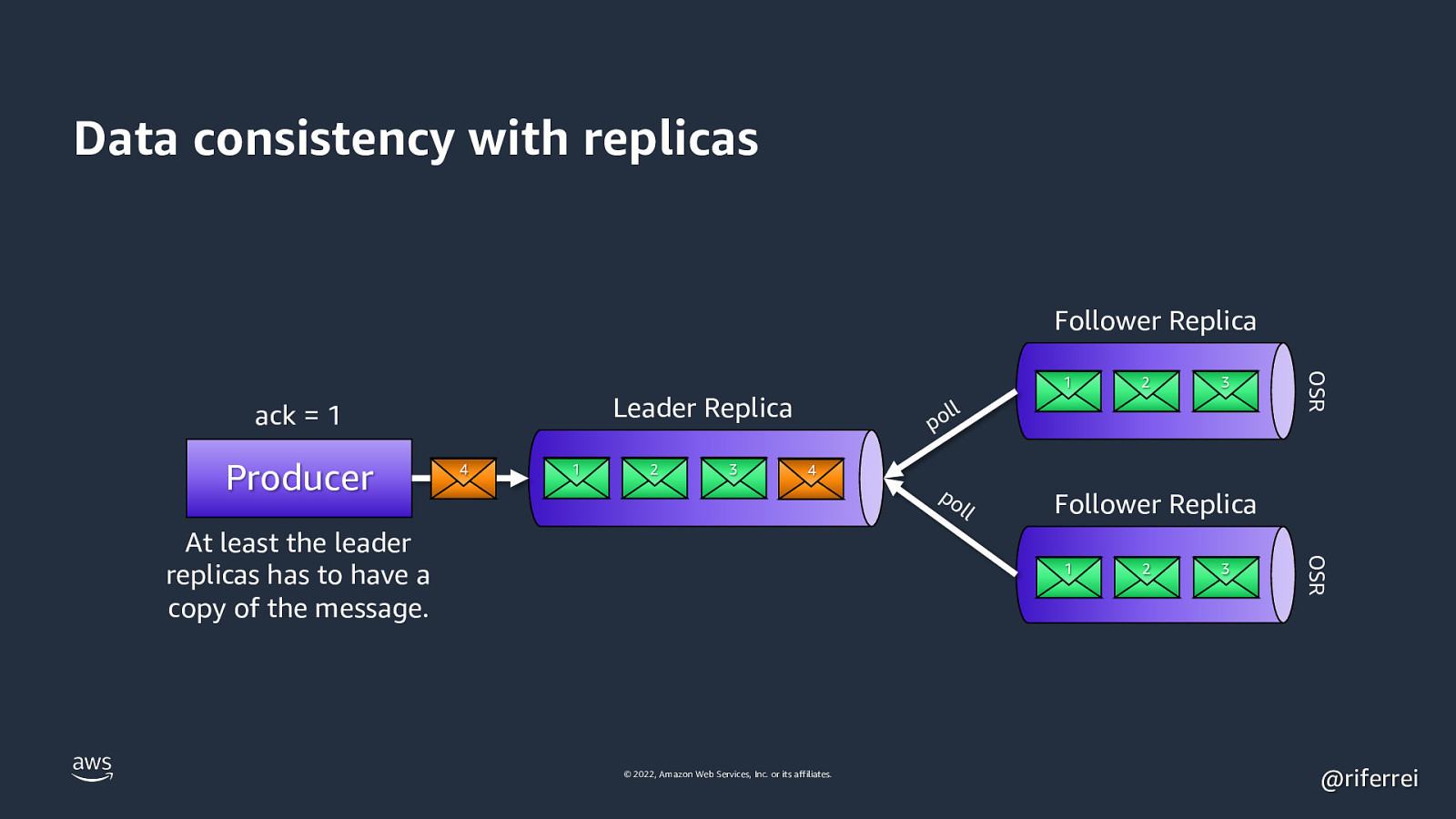
Data consistency with replicas Follower Replica 4 1 2 3 2 3 ll po 4 l Follower Replica 1 © 2022, Amazon Web Services, Inc. or its affiliates. 2 3 OSR At least the leader replicas has to have a copy of the message. po l OSR Leader Replica ack = 1 Producer 1 @riferrei
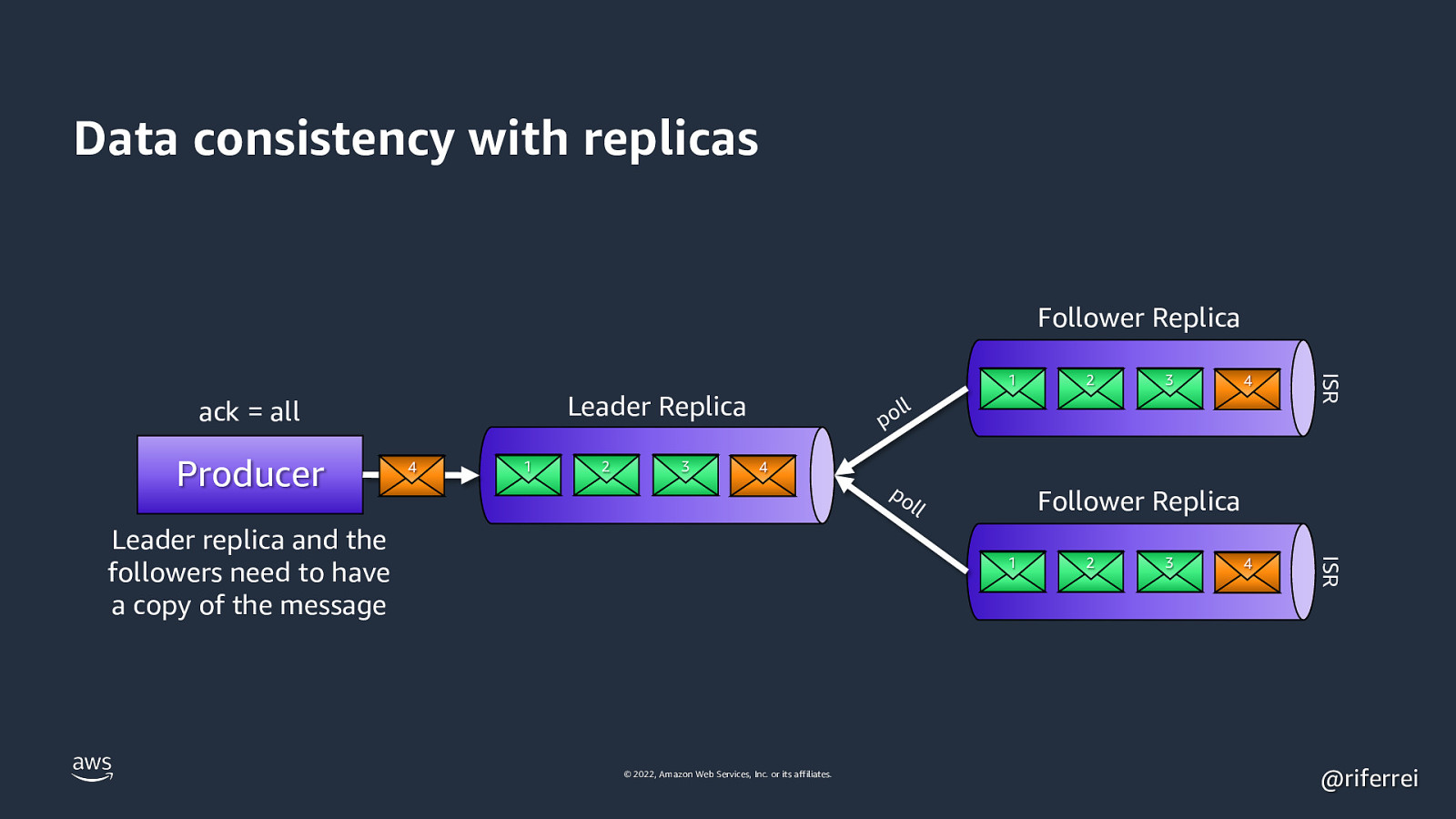
Data consistency with replicas Follower Replica Producer 4 1 2 3 3 4 4 ISR Leader Replica ack = all 2 ISR 1 ll po 4 Leader replica and the followers need to have a copy of the message po l Follower Replica l 1 © 2022, Amazon Web Services, Inc. or its affiliates. 2 3 @riferrei
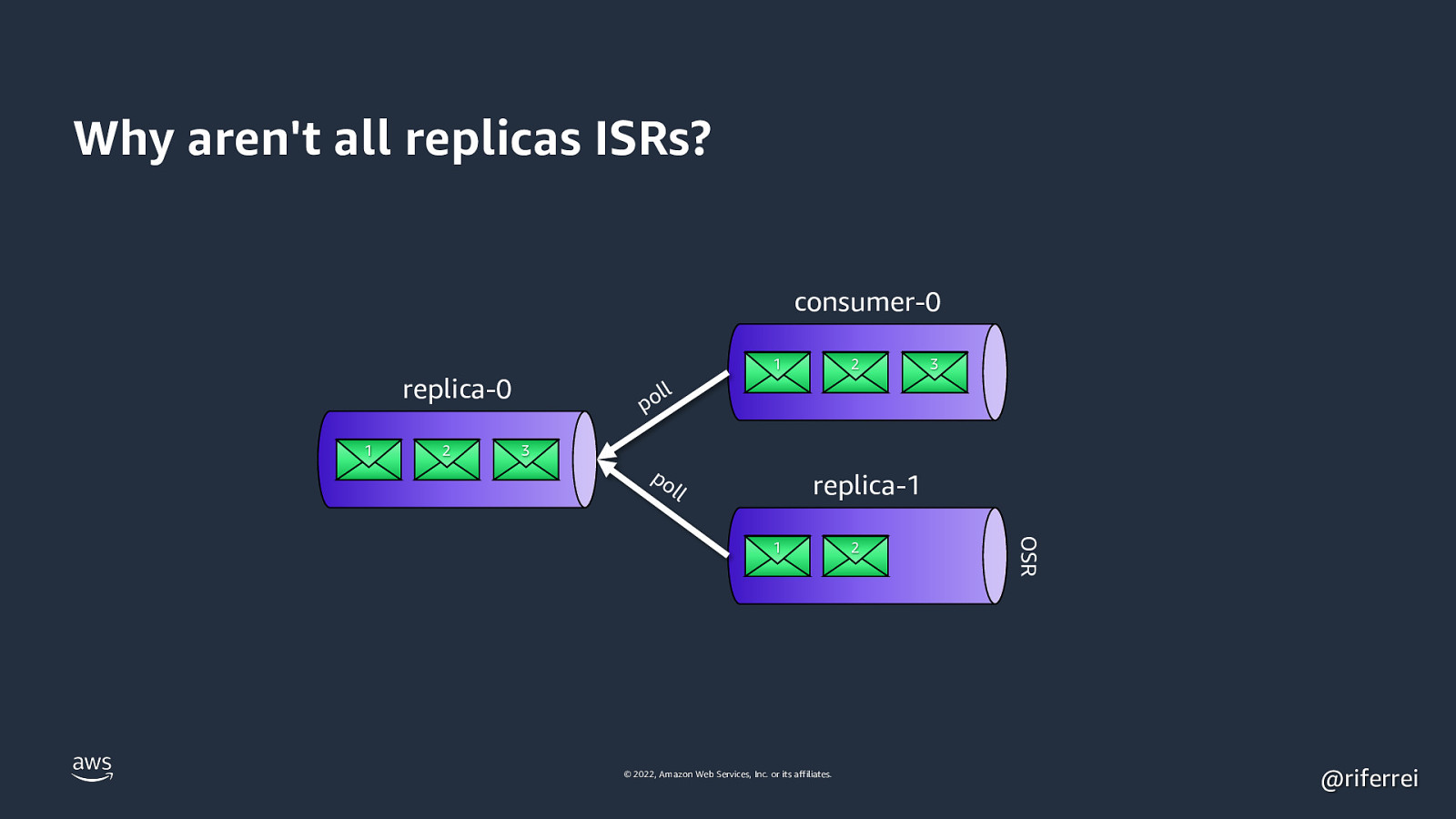
Why aren’t all replicas ISRs? consumer-0 1 replica-0 1 2 2 3 ll po 3 po l replica-1 l © 2022, Amazon Web Services, Inc. or its affiliates. 2 OSR 1 @riferrei
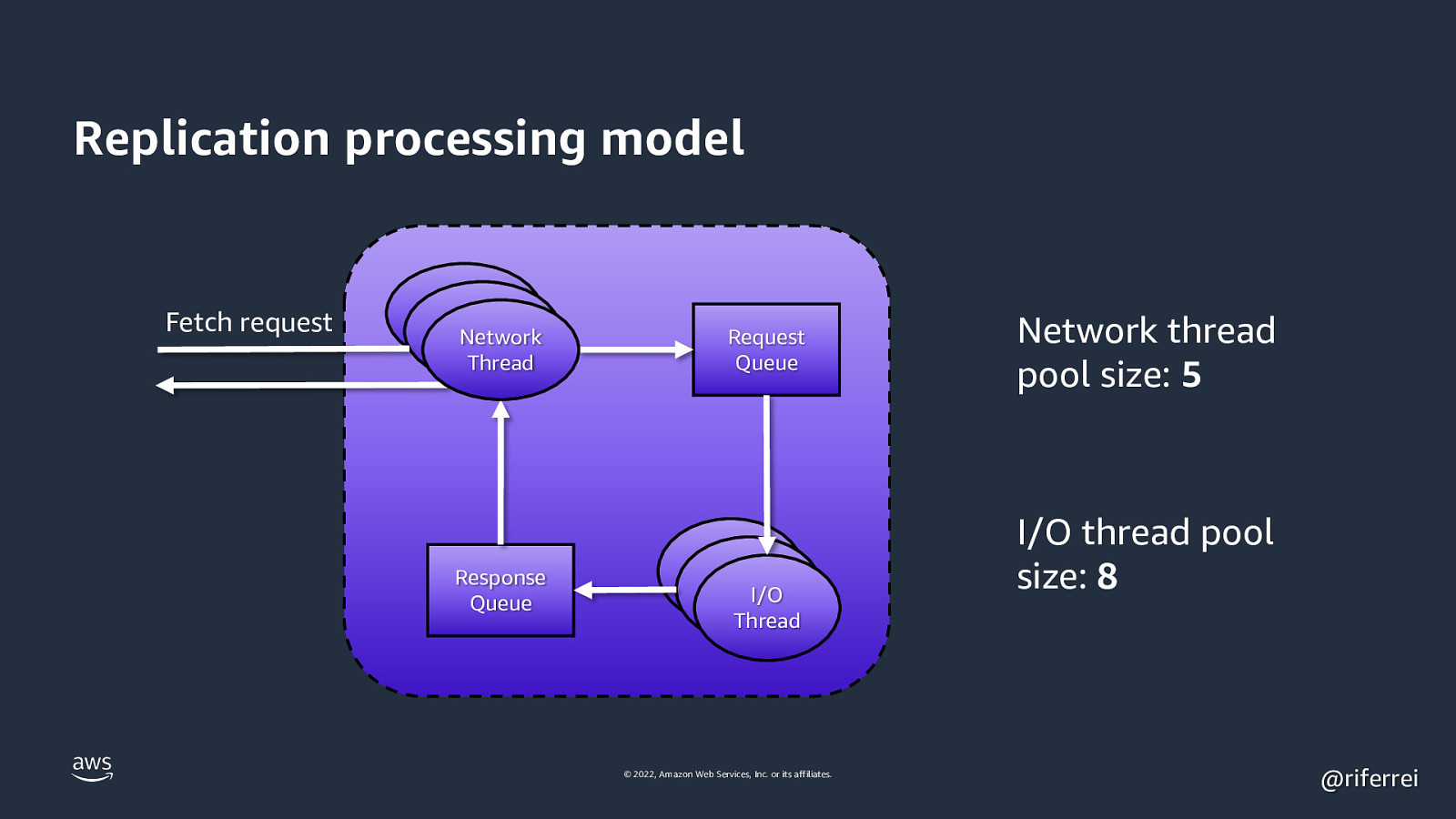
Replication processing model Fetch request Network Thread Response Queue Request Queue Accepto Accepto r Thread I/O r Thread Thread © 2022, Amazon Web Services, Inc. or its affiliates. Network thread pool size: 5 I/O thread pool size: 8 @riferrei

Quiz time: • Broker with default configuration. • You notify lag with replication. • Network pool increased to 10. • I/O thread pool increased to 16. Will this solve the problem? 🤔 © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Result: No. Usually the replication saturation occurs in a network interface level, before any need of more CPU power. In fact, if you increase these thread pools without having enough CPU idle, there is a huge change of you making the problem even worst with lots of context switching. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

This session is also available as a blog post: https://www.buildon.aws/posts/in-the-land-of-the-sizing-the-one-partition-kafka-topic-is-king/01-what-are-partitions/ © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Thank you! Ricardo Ferreira @riferrei © 2022, Amazon Web Services, Inc. or its affiliates. © 2022, Amazon Web Services, Inc. or its affiliates. @riferrei

Every technology has that key concept that people struggle to understand. With databases, is which join clause to use for fetching data from multiple tables. Containers are tricky when you have to pick a storage type given some persistence requirements. With Apache Kafka, the winner is how many partitions to set for a topic.
Why this is important? You may ask. Well, sizing Kafka partitions wrongly affects many aspects of the system, such as consistency, concurrency, and durability. Worse, it may also affect how much load Kafka can handle. Hence why often the decision about how many partitions to set for a topic is handled by Ops teams, as we see this to be only an infrastructure matter. In reality, this is an architectural design decision that affects even the amount of code you write.
This session will peel off the concept of partitions and explain it from the perspective of the Kafka cluster and its clients. By using a what-if presentation style, it will explain the overall impact on the system given a number. This will help you build more confidence about how to size Kafka partitions correctly, and to spot a poor decision when you see one.
Video
Resources
The following resources were mentioned during the presentation or are useful additional information.
Code
The following code examples from the presentation can be tried out live.